{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于神经网络的时变无线信道仿真
[刘留1, 2  , 李慧婷
, 李慧婷1 , 张嘉驰1 , 李一倩1 , 周涛1 ]
, 李慧婷|
|


第一作者:刘留(1981—),男,云南昆明人,教授,博士,博士生导师.研究方向为无线信道测量与建模和时变信道通信信号处理.email:liuliu@bjtu.edu.cn.
提高频谱利用率、实现超大容量传输的前提是精准掌握无线信道特性信息.研究了反馈神经网络(Back Propagation Neural Network, BPNN)在无线信道多普勒功率谱仿真中的应用.利用大量样本训练BPNN实现对时变信道进行预测.仿真结果表明,与传统方法对比,BPNN的仿真效果更接近理论值,误差更小,具备很好的容错性,同时模型输出结果的频域呈U型谱,时域自相关函数满足第一类贝塞尔函数,很好地符合Jakes模型的时频域条件.对3种方法的时间复杂度进行比较,结果表明BPNN的时间复杂度最高,牺牲了时间复杂度但换取了高精度和低误差.对3种误差逆向传播算法的仿真结果进行对比,发现列文伯格-马夸尔特( Levenberg-Marquardt, L-M)算法训练BPNN的均方误差最低,效果最佳.
In order to improve the spectrum utilization rate and realize ultra-large capacity transmission, the premise is to accurately grasp the wireless channel characteristic information.This paper studies the application of Back Propagation Neural Network (BPNN) in Doppler power spectrum simulation of wireless channel. BPNN is trained by using a large number of samples to predict time-varying channels. The simulation results show that compared with traditional methods, BPNN simulation results are closer to theoretical values, with less errors and good fault tolerance. At the same time, the frequency domain of the model output results is U-shaped spectrum, and the time domain autocorrelation function satisfies the first type of Bessel function, which is in good accordance with the time-frequency domain conditions of Jakes model.The time complexity of the three methods is compared. The results show that BPNN has the highest time complexity, sacrificing the time complexity but obtaining high precision and low error. Besides, the simulation results of three error back propagation algorithms are compared. It is found that Levenberg-Marquardt algorithm has the lowest mean square error and the best effect in training BPNN.
无线信道作为信号传输的媒介, 其性能的好坏直接决定着通信的质量.为在有限的频谱资源上尽可能地高质量、大容量传输有用信息, 就要求设计者必须清楚地了解信道的特性, 掌握电波在信道中的传播及变化规律, 即建立精准的信道模型[1].
信号在信道中传输会产生衰落, 衰落又通常分为大尺度衰落和小尺度衰落.大尺度衰落表征了接收信号在一定时间内的均值随传播距离和环境的变化呈现的缓慢变化, 了解其特征主要用以分析信道的可用性、选择载波频率、切换及网络规划, 其规律相对简单, 已有很多成熟的模型.而小尺度衰落表征了接收信号短距离(几个波长)或短时间内的快速波动, 是移动信道的主要特征, 其中Clarke信道模型描述的小尺度平坦衰落信道中, 移动台接收信号具有基于散射方式的场强统计特性, 这正符合市区移动通信环境不存在直射路径的特点, 其包络统计特性服从瑞利分布, 因此又称为瑞利衰落信道模型[2].然而Clarke参考模型是一种理想模型, 物理不可实现, 实际应用中通过正弦波叠加法和成型滤波法两种来实现时变信道仿真.但上述两种传统方法存在着种种缺陷, 如:正弦波叠加法的精度较低, 而成型滤波法的计算量较大, 不适宜用于大数据量的信道仿真[3].
随着人工智能的发展, 机器学习和无线通信的结合也吸引了众多学者的关注.已有相关工作研究了机器学习, 尤其是神经网络在无线传输层中的应用.文献[4]基于神经网络对多径信道的输入输出响应进行了建模, 讨论了建模的方法并给出了仿真的结果.文献[5]基于多层前向神经网络研究了时变信道建模方法, 仿真结果表明前向神经网络可以很好地跟踪非稳态时变信道的特性.文献[6]基于深度学习搭建了深度MIMO(Multiple-Input Multiple-Output)检测器, 将梯度投影法的迭代过程展开成深度神经网络, 折中了算法的检测性能、复杂度与收敛性.然而这些研究的重点主要着眼于应用机器学习的方法解决无线信道建模的问题, 并没有对利用神经网络仿真时变信道中多普勒效应的问题进行深入研究.神经网络作为一种非线性统计性数据建模工具, 具有极强的学习能力, 能在复杂情况下逼近非线性系统, 具有很好的容错性和鲁棒性.利用神经网络学习预测时变信道模型, 可以降低数据计算量, 而且拥有高精度和强灵活性[7].
本文作者研究了反馈神经网络(Back Propagation Neural Network, BPNN)在无线信道多普勒功率谱仿真中的应用, 利用传统的正弦波叠加法和成型滤波法产生的大量多普勒功率谱训练样本数据, 通过训练BPNN实现对时变信道进行预测, 将仿真结果进行了对比分析.并对3种方法的时间复杂度进行了讨论.此外, 还对3种常见的误差逆向传播算法的预测效果进行了比较.
信号在移动信道中传输, 由于受到衰落和噪声的影响, 导致信号强度、频率等发生相应变化.
小尺度平坦衰落信道中[8], 由于周边散射物的影响, 导致接收端接收到的是来自不同路径的多径信号.同时, 移动的移动台将会导致每条多径分量具有不同的多普勒频移.假设移动台接收的信号的入射角度
式中:
接收信号的自相关函数为
式中:
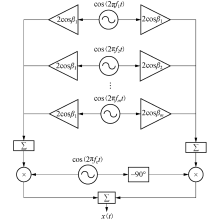
正弦波叠加法是利用确定性过程来模拟随机过程.根据概率论和瑞利分布的定义, 多个不同频率的正弦波叠加, 其幅度服从高斯分布.当实部和虚部均用多个不同频率的正弦波叠加, 则实部、虚部均分别服从高斯分布.而两个高斯变量的平方和的根服从瑞利分布, 因此包络服从瑞利分布[10].正弦波叠加法易于实现、占用计算资源少, 但是产生的多普勒功率谱是由多个离散频率点上的冲激构成, 并且自相关性能不够理想, 因而实际应用中常采用的是基于正弦叠加法的Jakes仿真模型[11], 其框图见图1.其中
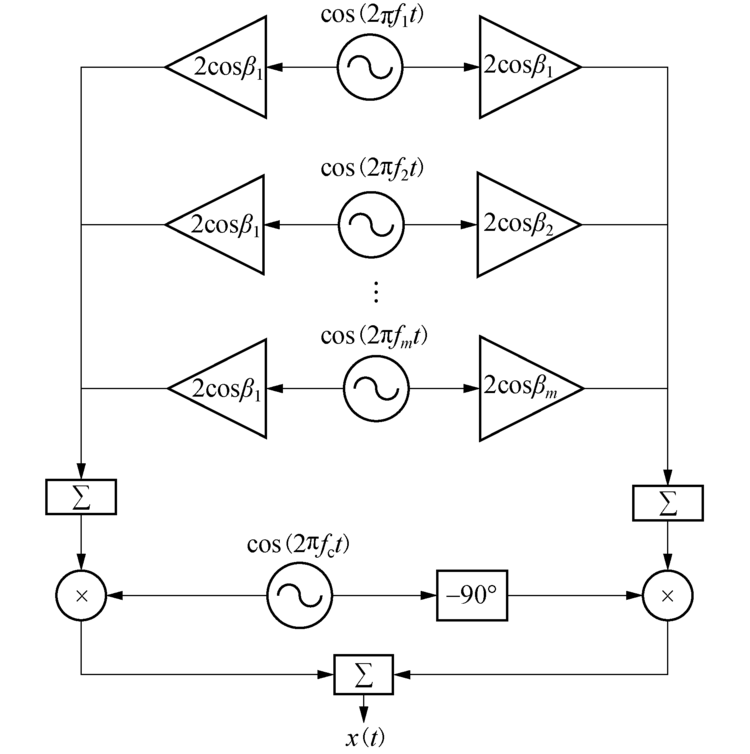 | 图1 Jakes正弦波叠加法仿真模型实现框图Fig.1 Jakes sinusoidal superposition method simulation model implementation block diagram |
图1的左右两支路都由多个不同频率的正弦波叠加, 其中:
式中:
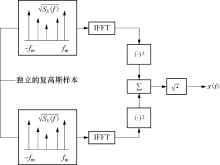
成型滤波法的仿真结构如图2所示, 它是将高斯白噪声输入成型滤波器来产生指定形状的多普勒功率谱, 其中
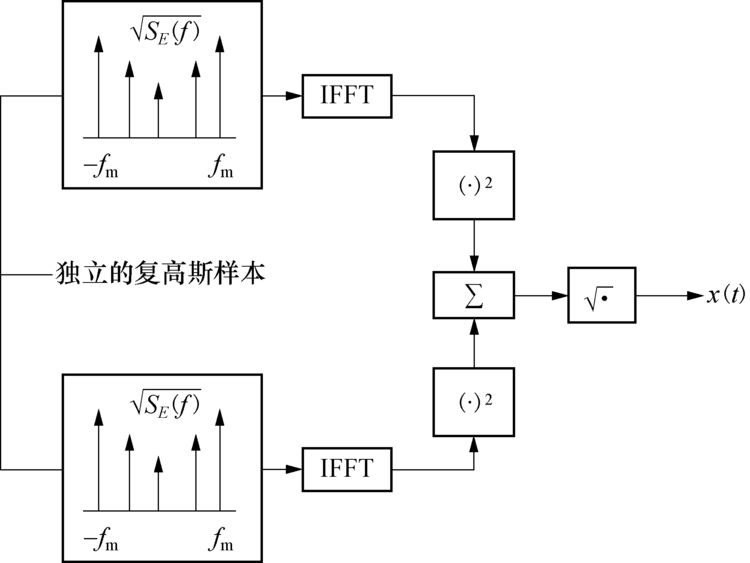 | 图2 成型滤波法仿真模型实现框图Fig.2 Blocking filter simulation model implementation block diagram |
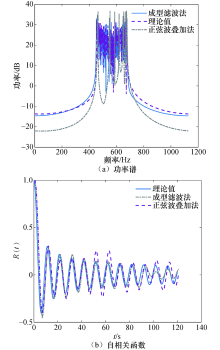
 | 图3 基于两种方法得到的功率谱和自相关函数Fig.3 Based on the power spectrum and autocorrelation functions obtained by the two methods |
自相关函数也都基本符合第1类贝塞尔函数, 由正弦波叠加法得到的曲线的中部和尾部起伏较大, 并不总是符合衰减特性, 由此可说明成型滤波法的误差小于正弦波叠加法.成型滤波法采用的是随机噪声, 因而随机性等各方面性能都比正弦叠加法更为理想.由于通常情况下通信系统的采样速率非常高, 最大多普勒频率与采样率相比很小, 因此成型滤波器需要的带宽很小, 直接实现非常困难.
通信信道可以看作一个非线性的复杂系统.当对一个非线性系统采用神经网络进行建模时, 假设x表示系统的
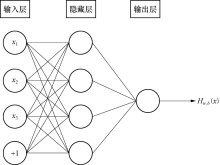
根据Kolmogorov定理[15], 3层网络经过充分学习后能几乎逼近任何函数, 所以建立如图4所示的3层结构的神经网络进行学习训练.神经网络的核心思想中经过不断地训练, 找到一个合适的参数拟合输入输出的映射关系.理论上, 神经网络可以拟合任意线性或者非线性的函数.
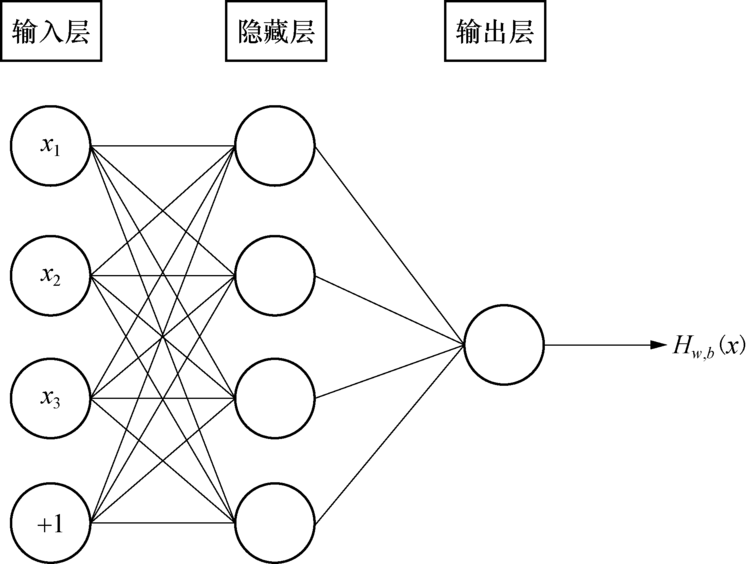 | 图4 三层神经网络结构图Fig.4 Structure diagram of three-layer neural network |
采用BPNN对信道模型进行预测, 训练模型逼近时变信道的输入输出关系.BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络, 误差反向传播算法就是寻找合适
1)将信道参数进行归一化预处理.
首先, 利用传统的正弦波叠加法和成型滤波法产生的大量多普勒功率谱样本数据作为输入信号, 再利用BPNN进行训练之前需要将输入数据进行归一化预处理, 采用min-max标准化方法, 即可将原始数据的取值范围映射到
然后将归一化后的样本数据按输入层→ 隐含层→ 输出层的方向传递, 经过非线性变换, 产生输出信号.当各层神经元的激活函数均采用sigmod函数, 表达为[17]
式中:
更新公式如下
式中:
2)信号正向传输, 计算网络总误差
3)将实际输出与期望输出相比较, 如果不相符, 计算
式中:
4)将从各层获得的误差信号作为调整各单元的权值的依据, 使用残差来更新权值
5)反复上述学习训练过程, 直至求得的误差小于设定阈值或者达到诸如训练次数等迭代训练要求.确定与最小误差相对应的网络参数(权值和阈值), 训练停止[18].
常见的误差逆向传播算法是梯度下降法, 它是使用最广泛的最小二乘最优化算法[19].梯度下降法以负梯度方向作为极小化算法的下降方向, 是无约束优化中最简单的方法, 它具有储存量小、结构简单、易于实现等优点, 但其缺点在于:在远离鞍点的地方下降很快, 而在靠近鞍点的地方下降很慢, 且损失函数可能收敛到鞍点[20].
另一种使用广泛的方法是高斯牛顿法, 它是一种非线性最小二乘最优化方法.其利用了目标函数的泰勒展开式把非线性函数的最小二乘化问题化为每次迭代的线性函数的最小二乘化问题.高斯牛顿法的缺点在于:若初始点距离极小值点过远, 迭代步长过大会导致迭代下一代的函数值不一定小于上一代的函数值[21].
鉴于梯度下降法和高斯牛顿法的缺点, 本文采用的误差逆向传播算法是列文伯格-马夸尔特(Levenberg-Marquardt, L-M)算法.在L-M算法中, 每次迭代是寻找一个合适的阻尼因子
1)L-M算法需要对每一个待估参数求偏导, 因此当拟合函数
2)对于非常大的数据集和神经网络, L-M算法的Jacobian矩阵会变得很大, 需要的内存也较大.因此L-M算法不太适合应用于大数据集的情况.
利用Matlab进行BPNN训练, 仿真参数设置为:每层节点数为100, 隐含层层数为1, 训练次数为1 000, 设定误差为0.1, 训练集为70%, 测试集/验证集为15%, 输入层神经元数为100, 隐含层神经元数为80, 输出层神经元数为100.神经网络对于隐含层层数的要求是大于等于1, 而隐含层数量过高时, 准确率可能反而会下降, 这是因为反向传播算法中的梯度经过越多的隐含层就会越小, 并逐渐趋近于零, 这种现象称为梯度消失或梯度弥散.因此层数越多越容易发生过拟合, 均方误差可能增大, 故设置隐含层数为1.另外通过误差与节点数的测试, 选择误差最小时的节点数80.首先通过正弦叠加法和成型滤波法得到大量多普勒功率谱训练样本数据, 用来训练神经网络, 其中训练集占70%、测试集和验证集各占15%.
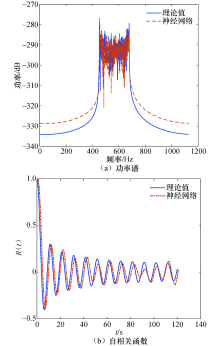
由神经网络学习预测得到的结果见图5.
 | 图5 神经网络预测效果Fig.5 Neural network prediction effect |
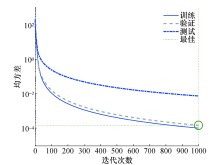
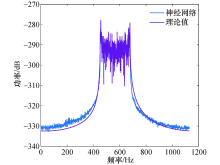
可以看到神经网络预测值的频域符合U型谱, 时域的自相关函数符合第1类贝塞尔函数, 因此神经网络预测值符合Jakes模型.神经网络训练1 000 次后的均方误差效果如图6所示, 可以看到均方误差随着训练次数的增加而下降, 圆圈表明训练得到最小均方误差的时间, 即在训练第999次时均方误差达到最小值1.43× 10-4, 说明BP神经网络模型预测精度很高.
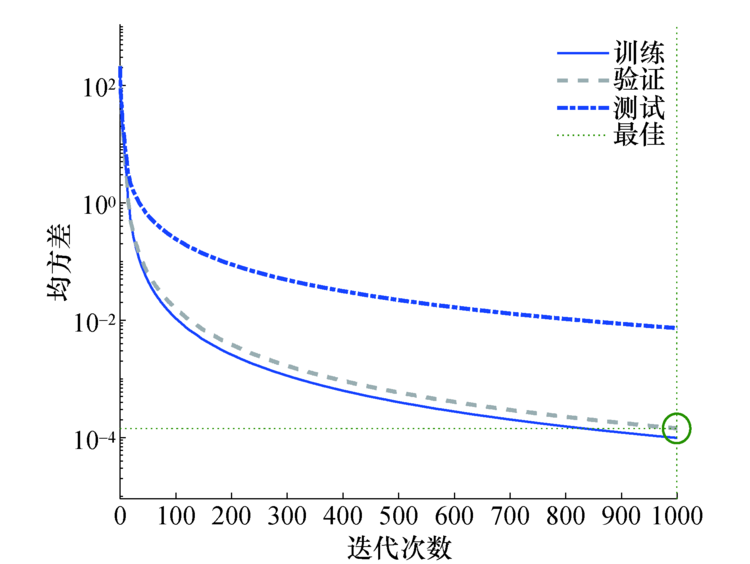 | 图6 迭代次数与均方误差关系Fig.6 Relationship between iteration times and mean square error |
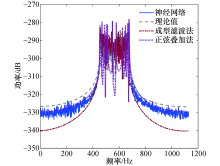
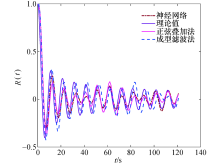
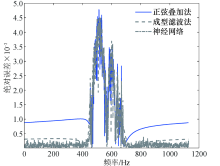
随后, 将神经网络预测值与正弦波叠加法、成型滤波法以及理论值比较, 多普勒功率谱对比效果如图7所示, 可以看到神经网络预测得到的多普勒功率谱更接近理论值, 而正弦波叠加法和成型滤波法得到的多普勒功率谱虽也符合U型谱的特征, 但与理论值存在较大的差异.自相关函数对比如图8所示, 可以看到神经网络预测得到的自相关函数更接近理论的第1类贝塞尔函数, 而由正弦波叠加法和成型滤波法得到的自相关函数, 在曲线的中部和尾部起伏较大, 并不总是符合第1类贝塞尔函数的衰减特征, 因此由神经网络预测的拟合程度更高.神经网络预测、正弦波叠加法及成型滤波法三者与理论值的绝对误差对比如图9所示, 可以看到神经网络预测的误差更接近于0, 其次是成型滤波法和正弦波叠加法, 说明神经网络预测的误差低于传统的两种方法.由此可见, 利用神经网络对时变信道仿真建模比传统方法的精度更高.
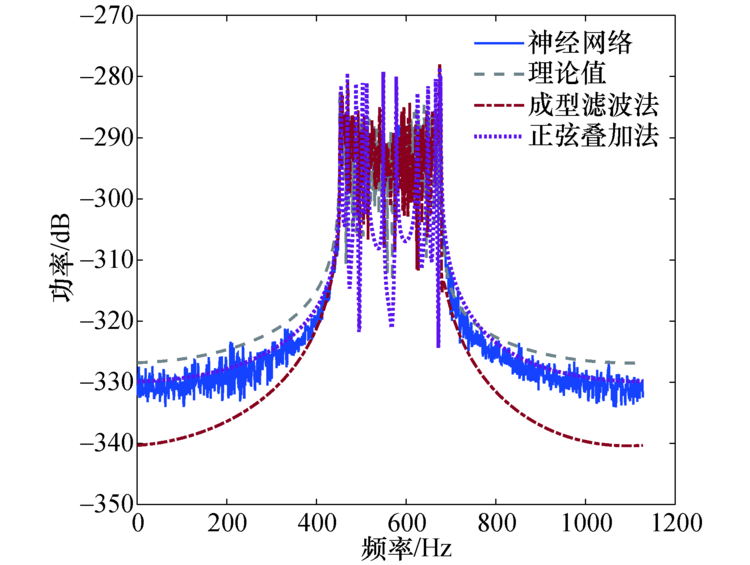 | 图7 功率谱对比Fig.7 Power spectrum comparisons |
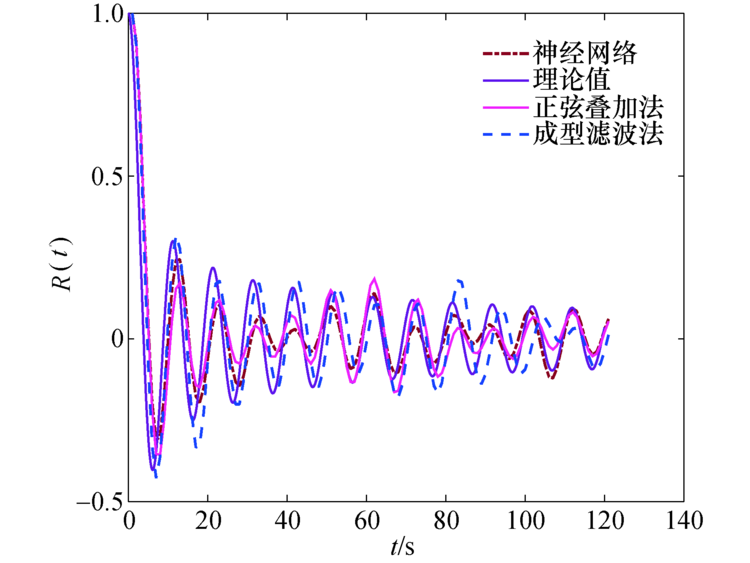 | 图8 自相关函数对比Fig.8 Autocorrelation function comparisons |
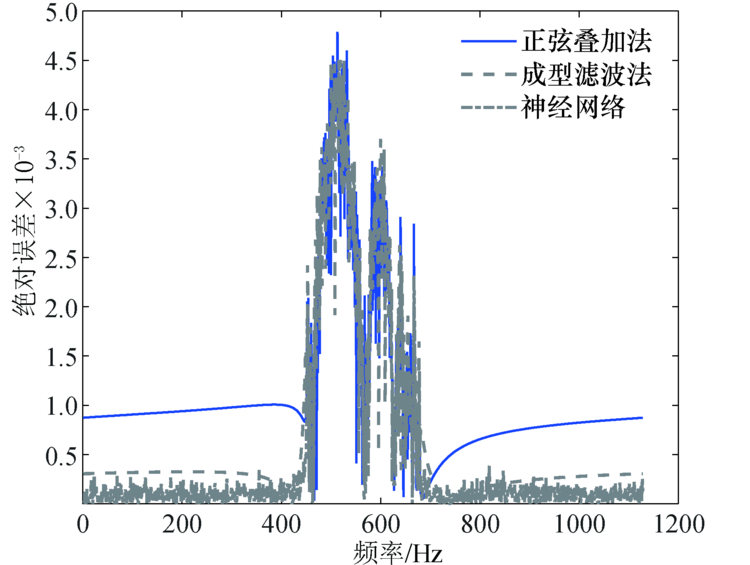 | 图9 绝对误差对比Fig.9 Absolute error comparison |
神经网络对被建模的输入输出数据对进行充分学习, 训练好的网络模型可对实际数据进行仿真.神经网络仿真数据与理论值进行比较, 如图10所示, 可以看到拟合程度非常高, 说明训练好的网络模型精度极高, 能较好地预测U型谱.
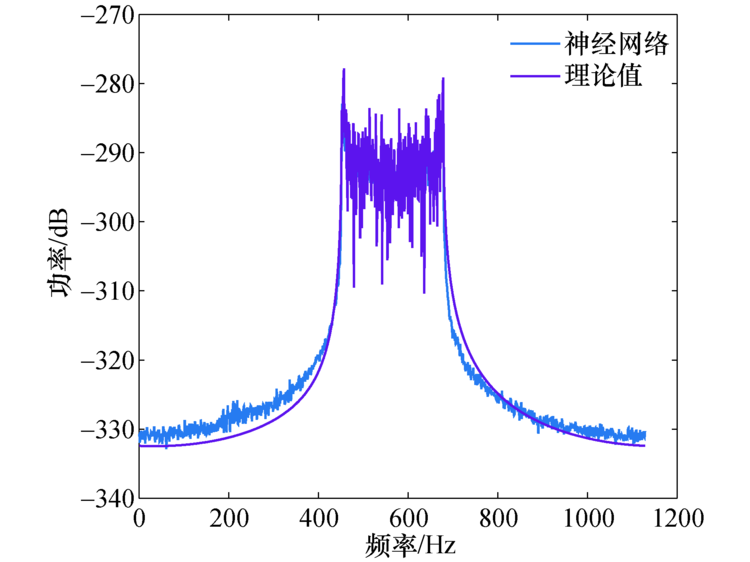 | 图10 神经网络仿真数据Fig.10 Neural network simulation data |
正弦波叠加法对Clarke理论模型进行了简化, 仿真所需的低频振荡器(即正弦波发生器)数目由
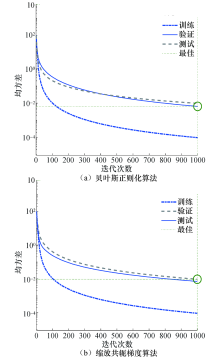
分别使用贝叶斯正则化(Bayesian regularization)算法和缩放共轭梯度(Scaled conjugate gradient)[24]这两种算法来训练BP神经网络, 得到的均方差如图11所示.可以看到, 在相同训练次数前提下, 利用贝叶斯正则化算法训练BP神经网络得到的均方差为6.45× 10-3(第998次), 利用缩放共轭梯度算法为9.17× 10-3(第997次), 均高于由L-M算法训练的均方差1.43× 10-4.因此L-M算法训练BP神经网络的精度更高.
 | 图11 其他算法训练得到的均方差Fig.11 Mean square error obtained from training of other algorithms |
贝叶斯正则化算法略优于缩放共轭梯度算法, 对于困难的、小的或有噪声的数据集可以产生良好的泛化能力, 但它通常需要更多的时间, 根据自适应权重最小化(正则化)停止训练.缩放共轭梯度算法训练需要的时间短, 因为其需要的内存较少.当泛化能力停止提高时, 训练会自动停止, 验证样本的均方误差会增加[25].
1)利用传统方法产生的大量多普勒功率谱样本数据, 训练神经网络对时变信道进行学习预测, 训练好的网络结构仿真出来的结果频域符合多普勒功率谱的特征, 呈U型谱.时域自相关函数满足第1类贝塞尔函数, 很好地符合Jakes模型的时频域条件, 均方误差达到1.43× 10-4, 说明BP神经网络模型预测精度很高, 能较好地预测U型谱.理论上, 只要给神经网络输入足够样本数量的训练数据集进行充分学习, 训练好的网络模型即可用于预测具有更多影响因素的无线信道.
2)与传统的正弦波叠加法、成型滤波法仿真结果对比, 神经网络的仿真效果更接近理论值, 说明其效果优于传统方法, 同时具备具有很好的容错性.对3种方法的时间复杂度进行比较, 结果表明BPNN的时间复杂度最高为
3)对3种误差逆向传播算法的仿真结果进行对比, 发现L-M算法训练BPNN的均方误差最低, 效果最佳.此外, 还对比了3种不同的误差逆向传播算法的预测效果, 仿真结果表明, L-M算法训练BP神经网络的精度最高, 贝叶斯正则化算法和缩放共轭梯度算法次之.
在后续研究中, 还将针对不同时变信道场景测试神经网络对其建模可行性及网络模型的可复用性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|