{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
QL-OLSR:一种基于Q-Learning思想优化的移动自组织网络路由协议
[熊轲 , 金鑫, 刘强]
, 金鑫, 刘强]
, 金鑫, 刘强]
|
|


第一作者:熊轲(1981—),男,陕西汉中人,教授,博士,博士生导师.研究方向为移动互联网络,物联网,5G 网络等.email:kxiong@bjtu.edu.cn.
现有的OLSR中能够完成对全网路由信息的交互,但是随着节点的移动速度增加,网络拓扑也在快速动态变化,从而导致了路由信息更新慢,网络性能下降,端到端时延大、包丢失率增加和节点吞吐量小等问题.针对上述问题,提出了一种基于Q-Learning思想的移动自组网OLSR路由策略,该路由策略从节点移动性、链路速率和节点跳数三方面进行考虑.与传统方法相比,Q-Learning能够在线学习,适应MANET高度动态变化的拓扑结构,检测不同时间点的节点移动程度,使每个节点能相应的更新路由度量,从而提高路由协议的稳定性,提供可靠的路由路径.实验结果表明,改进的方法具有更低的端到端延迟、更小的包丢失率以及更高的吞吐量.
The existing OLSR can complete the interaction of the routing information of the whole network. However, as the moving speed of the node increases, the network topology also changes rapidly and dynamically, which leads to slow update of routing information, large end-to-end delay, increased packet loss rate, low node throughput, and reduced network performance. Aiming at the above problems, this paper proposes a mobile ad hoc network OLSR routing strategy based on Q-Learning idea. The routing strategy considers node mobility, link rate and node hop count. Compared with the traditional method, Q-Learning can learn online, adapt to the highly dynamic topology of MANET, and detect the degree of node movement at different time points, so that each node can update the routing metric accordingly, thus improving the stability of the routing protocol, providing a reliable routing path. Experimental results show that the improved method has lower end-to-end delay, smaller packet loss rate, and higher throughput.
移动自组织网络[1](Mobile Ad Hoc Networks, MANETs)又被称为无线自组织网络(Wireless Ad Hoc Networks)、多跳网(Multi-hop Network), 它是一种新型、多跳、自组织、无中心的无线网络.移动自组网最开始在军事方面应用, 保持通信联络在现代化的战场上是十分重要的事情.在自组网中, 每个用户节点不但能够自由移动, 同时还拥有路由器和主机两个功能[1].一是作为主机, 终端需要运行各种面向用户的应用程序; 另一方面, 作为路由器, 终端运行相应的路由协议, 然后通过路由策略和路由表来完成对数据的分组转发和路由维护.因此, 路由协议是MANET网络中一个重要的研究问题.一般情况下, 根据不同的路由发现策略, 将路由协议分为先验式路由协议、反应式路由协议以及混合式路由协议[2].在先验式路由协议中, 到达所有目的节点的路由在开始时就已决定, 通过定期的路由更新进程来维持, 典型的先验式路由协议有OLSR(Optimized Link State Routing Protocol).在反应式协议中, 路由是在数据源使用路由发现进程发出请求决定的, 典型的反应式路由协议有AODV(Ad hoc On-Demand Distance Vector Routing).
通过文献[3]对两种协议的对比可知, 由于OLSR无论是否有通信需求, 每个节点都周期性地进行路由分组广播, 通过交换路由信息, 维护一张到达其他节点的路由表, 节点一旦需要发送报文, 就可以根据路由表及时获取路径信息; 而AODV采用的是一种当有业务要发送时才查找路由的选择方式, 当有需要发送数据时才发起路由查找过程, 不能提前获知全网的拓扑, 所以时延相对OLSR要大; OLSR的主要特点是通过在本节点的邻居节点中选择一部分节点作为多点中继(MPR)节点, 只有MPR节点才能转发TC控制分组, 以此来减少控制消息的洪泛.所以, 随着业务的增多, AODV路由开销几乎成正比例增长, 而OLSR的路由开销不受业务数据产生大小的影响, 保持稳定.综上可知, OLSR路由协议在路由抖动、路由开销、平均端到端时延等方面要优于AODV等路由协议.
传统的路由协议难以适应节点快速移动, 拓扑快速动态变化的网络.现有针对OLSR的路由协议设计大多关注于路由的优化, 目的在于解决路由问题, 进而解决节点快速移动的问题.文献[4]引入模糊视觉技术, 自动调整消息的发送频率, 基于改变消息的传播机制对快速路由进行改进.文献[5]提出了一种基于Q-Learning的自适应路由模型QLAR用来检测网络中每个节点的移动程度以及新的度量Qmetric, 提出的新的度量考虑到了期望传输计数度量和移动因子度量, 使路由性能在移动性条件下得到, 但是提出的路由模型应用实验结果并未体现.文献[6]提出了一种基于链路感知的LR-OLSR路由协议, 该协议对节点负载、链路投递率和链路可用性等信息感知并进行路由表的计算, 提高吞吐量, 达到负载均衡, 用于无线Mesh网络.文献[7]提出了一种移动预测LP-OLSR协议, 该协议针对移动路由使用卡尔曼滤波对节点的位置进行预测, 预测链路未来时刻的连接状态, 在链路失效前重新计算路由, 减少因为链路中断产生的时延, 用于多径备份路由.文献[8]基于多目标Q-Learning提出了一种能够同时考虑信息报传输的跳数、传输的能量消耗、路径中节点的安全性的路由策略, 但是并没有实验结果证明, 只是提出了一种想法.文献[9]提出了使用Q-Learning来构作容错路由算法的方法, 利用Q-Learning算法的自适应性来实现路由容错, 但是它只在二维格子环境下的实验证明了算法的可行性, 并没有考虑到移动自组网络.
本文作者考虑了节点移动性、链路速率和节点跳数三方面特征, 提出了一种基于Q-Learning思想的OLSR路由协议策略, 它能够在线学习, 适应MANET高度动态变化的拓扑结构, 提高路由协议的稳定性, 提供可靠的路由路径.
目前在移动自组织网络中, 已经提出了许多通用的链路度量标准, 其中标准版的OLSRv1(RFC3626)使用Hop Count作为链路度量, 而在其后的OLSRv2版本中, 加入了Link Metric, 修改了路由消息格式, 设计成可以修改权值的形式.OLSR通过使用Dijkstra算法对网络拓扑对有向边的边权值进行计算, 从而获得路由度量值, 进而得出路由表, 选出最优的路由路径[10].为了保证网络具有低时延和高吞吐量, 一般路由权值设计考虑路径长度、链路稳定性、链路速率等因素.
本文主要借用文献[10]中针对链路稳定性和链路速率对路由权值设计优化的思想, 在此基础上, 基于节点移动性和链路速率对路由度量进行优化.
1.1.1 基于节点移动性的度量优化
在MANET网络中, 特别是在移动自组网中, 由于节点的快速移动, 从而导致链路变化速度快, 节点周围的链路稳定性影响路由质量, 所以, 当链路不稳定时, 就会造成高时延, 从而降低网络性能.为了保证MANET的性能, 文献[10]中提出了MF(Neighbor node’ s Mobility Factor)和AER(Neighbor node’ s Average Encounter Rate)两种基于链路稳定性的方法.但是只考虑了AER, 具有片面性, 所以本文将这两种方法结合.
MF即邻居节点的移动因子, MF的值是在连续交互2~3次Hello报文后, 邻居节点差异进行计算.其中Hello报文是OLSR路由协议中的一种控制消息报文, 用于发现邻居, 建立一个节点的邻居表, OLSR采用周期性地广播Hello报文来侦听邻居节点的状态, 而且Hello报文不同于OLSR的另一种控制消息报文, TC报文必须被广播到全网, 它只在一跳的范围内广播.
计算MF的公式如下
式中:
AER的计算公式如下
式中:
1.1.2 基于链路速率的度量优化
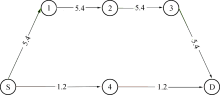
对于MANET网络, OLSR在建立路由时, 当数据包从一个节点传输到另一个节点时, 则认为经过一跳, 那么跳数越少, 端到端时延就会越少, 然而在无线网络中, 并不是跳数少的路由路径就是最佳的路由路径.举例如图1所示, 从源节点S到目的节点D, 跳数最少的路由路径为S→ 4→ D, 然而, 并不是最优路径, 因为S→ 4→ D路由路径的传输速率要低于S→ 1→ 2→ 3→ D路由路径, 跳数较多的路径反而最优.
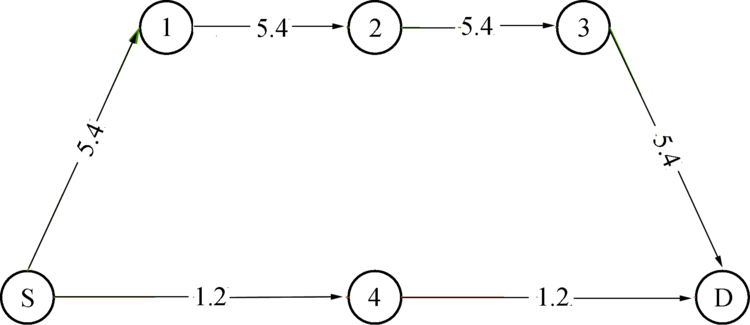 | 图1 路由路径选择(单位: M/bps)Fig.1 Routing path selected (unit: M/bps) |
由于链路速率可以在一定程度上反映链路的容量, 所以本文通过跨层设计获取下层数据的传输速率, 传输速率高的链路在单位时间内可以传输更多的信息.进而给出基于数据传输速率的路由度量(Routing Metric).第
式中:
1.2.1 Q-Learning简介
Q-Learning是一种不需要估计环境模型的强化学习算法.强化学习[11, 12, 13]是机器学习中的一个领域, 强调如何基于环境而行动, 以取得最大化的预期利益.强化学习与其他机器学习算法不同的地方在于:没有监督者, 只有一个奖励信号; 反馈是延迟的, 不是立即生成的; 时间在强化学习中具有重要的意义; 智能体的行为会影响之后一系列的数据.
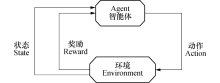
图2为强化学习的基本模型, 强化学习通过利用环境评价性回报信号来修正动作, 以极大化期望的回报为学习目标.智能体需要根据当前状态
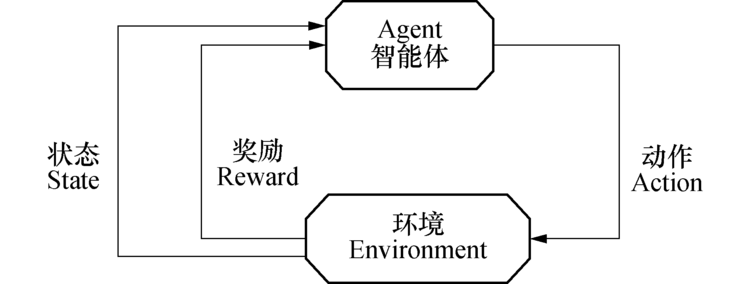 | 图2 强化学习基本模型Fig.2 Basic model of RL |
Q-Learning算法[14]的更新规则为
式中:
1.2.2 路由策略
本文提出的基于Q-Learning[15]的路由策略是将Q-Learning应用在OLSR路由协议中, 从而达到优化路由的作用.
针对本文提出的路由策略, 使用Q-Learning进行建模.首先Agent的学习环境为整个MANET网络, 学习网络中节点的移动性.学习过程是由一个三元组
在网络中, 每一个智能体Agent维护一个q表Q(d, n), 即每一个节点维护一张路由度量值表, 用来记录到达除本节点外所有节点的
| 表1 q表 Tab.1 q-table |
本文选择链路速率作为影响学习快慢的因素, 随着链路速率的变化, 节点的学习进度也跟着变化, 速率越快,
式中: d表示目的节点; n表示从当前节点i的一跳邻居节点中选择的下一跳节点; x表示目的节点的一跳邻居, 也就是从源节点到目的节点的过程中, 最后一个需要经过的节点;
Algorithm 1 QL-OLSR Routing Strategy
Input:QTable
Output:
1:
2://The interaction time of the Hello packet
3:
4:
5:for
6:
7:MF = Equation(1);
8:AER = Equation(2);
9://choose next hop node n
10:if isNextHop
11:RM = Equation(3);
12:
13:else
14:break;
15:end if
16:
17:
18:end for
19:
20:Return
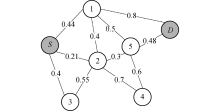
以一次建立路由路径的过程为例:如图3所示, 每一个节点的
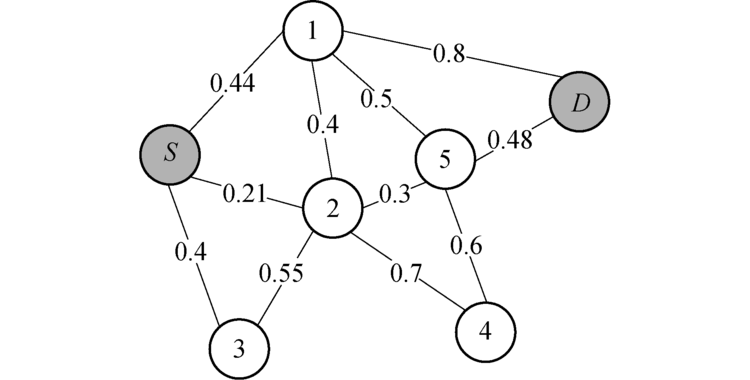 | 图3 网络拓扑示例图Fig. 3 An example of network topology |
综上, 可以从OLSR中的Dijkstra算法中计算路由路径得到从S到达D的具有最小q值的一条路径S→ 2→ 5→ D, 当节点的邻居节点有所变化的时候, 节点会动态更新自己的q表, 从而使网络能够动态适应拓扑的变化, 及时地做出响应.
实验采用OPENT Modeler 16.0进行建模和仿真, 构建基于Q-Learning思想的QL-OLSR协议模型, 并与标准版的OLSR协议进行结果分析对比.
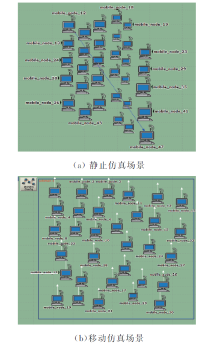
实验安装的OPNET16.0已经实现标准版的OLSR路由协议的软件包, 设置仿真参数如表2所示, 构建的仿真场景如图4所示, 使用IP业务流进行测试, 分别在静止和移动两种场景下对网络性能进行分析评估.
| 表2 仿真参数 Tab.2 Simulation parameters |
 | 图4 仿真场景Fig.4 Simulation scenarios |
在不同节点速度的场景下测试QL-OLSR, 并与标准版OLSR路由协议进行端到端时延、时延抖动、业务接收量和吞吐量对比分析.在网络拓扑中, 加入随机移动的模块, 设置节点的移动速率为0、5、10、15、20、25 m/s, 其他仿真参数条件不变.
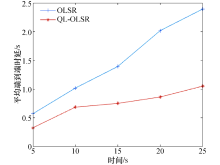
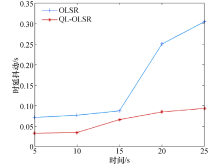
2.2.1 端到端时延和时延抖动结果分析
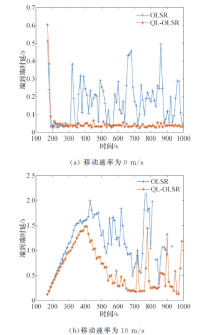
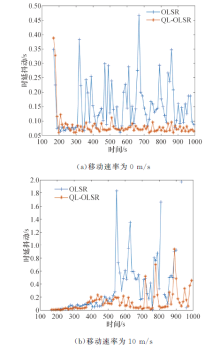
端到端时延和时延抖动结果如图5和图6所示.节点的移动速率在0、5、10、15、20、25 m/s情况下QL-OLSR与OLSR端到端时延和时延抖动对比, 可知, 随着节点移动速率的增加, 网络拓扑变化更快, 网络需要重新更新路由表.因此, 在节点移动速度不断变化的过程中, 节点的移动速度越快, 节点的平均端到端时延逐渐增加.但是QL-OLSR协议的延时要明显低于OLSR路由协议, 同时, 改进后的路由策略的时延抖动相对较小, 也较稳定, 没有特别大的变化, 这是由于加入了Q-Learning思想及考虑节点稳定性和链路速率后, 增加了节点稳定性, 可以快速适应网络拓扑的变化, 及时更新路由表, 从而减少由于信道堵塞造成的等待延时.端到端时延和时延抖动对比见如图7和图8.
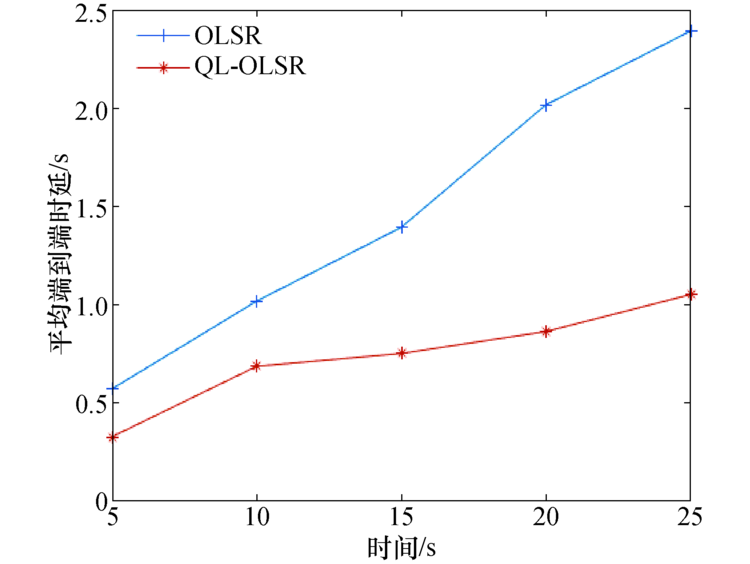 | 图5 平均端到端时延对比Fig.5 Average end-to-end delay comparisons |
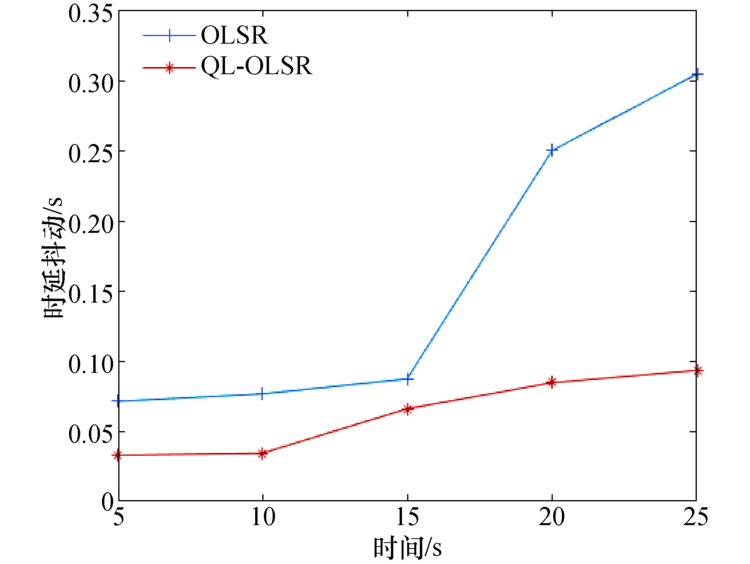 | 图6 平均时延抖动对比Fig.6 Average delay jitter comparisons |
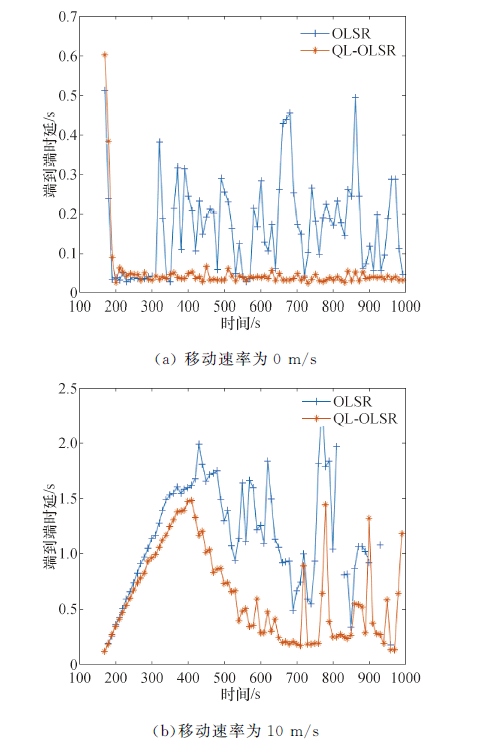 | 图7 端到端时延对比Fig.7 End-to-end delay comparisons |
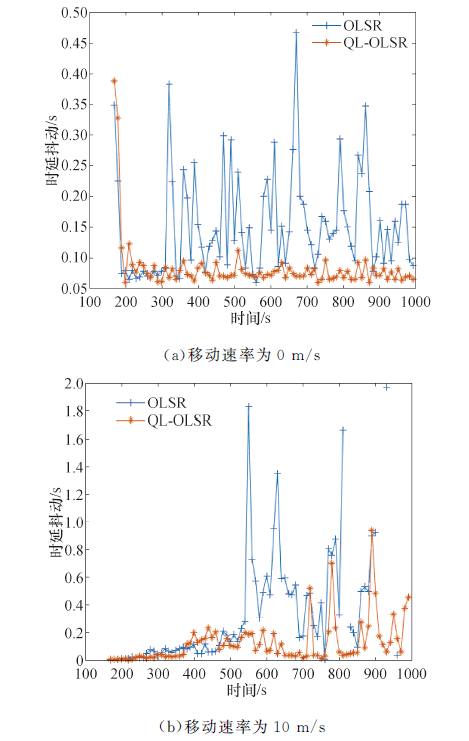 | 图8 时延抖动对比Fig.8 Delay Jitter comparisons |
可以得出:不论在静态场景还是在节点移动速率为10 m/s的情况下, 改进后的路由策略的网络更加稳定, 端到端时延也更低, QL-OLSR的时延抖动更小, 更加适应拓扑变化快的网络.
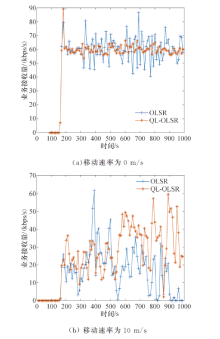
2.2.2 业务接收量结果分析
业务接收量如图9所示, 可以看出, 在静止的环境下(节点移动速率为0 m/s), QL-OLSR和OSLR两种协议的业务接收量差不多一致, 这是因为此时网络拓扑的变化情况不是很大.但是当节点移动速率增加时(节点速率为10 m/s), 两种协议的业务接收量就有了差距, 可以得出, QL-OLSR的业务接收量优于OLSR协议, 此时节点移动速率快, 网络拓扑变化快, 所以在接收业务时就需要更多的时间, 当信道堵塞时, 包就无法传输到目的节点, 从而造成包丢失的情况, 而QL-OLSR可以快速适应网络拓扑变化的过程, 故会有更小的丢包率, 更高的业务接收量.
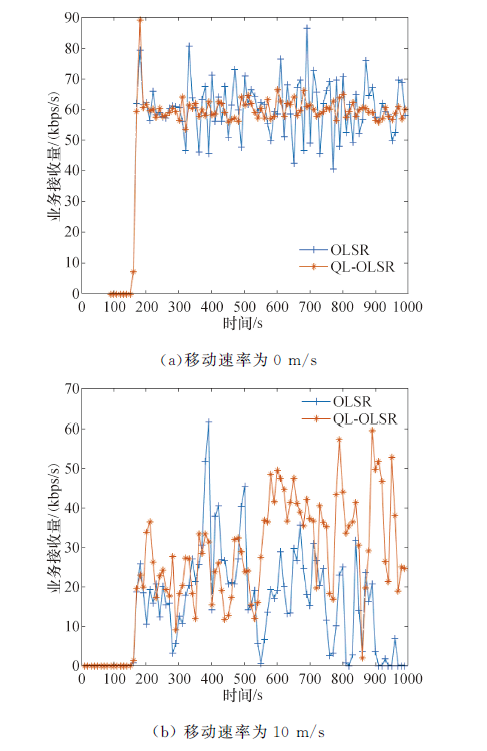 | 图9 业务接收量对比Fig.9 Received traffic comparisons |
此外, 可以看到在200 s时, 节点的业务接收量为0, 由于此时路由还未收敛, 源节点发送的包目的节点无法接收, 而在190 s之后, 路由收敛, 节点开始接收业务, 进而计算业务接收量.
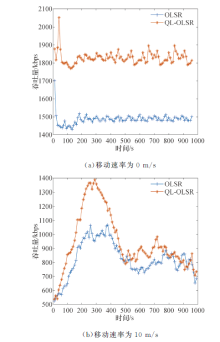
2.2.3 吞吐量结果分析
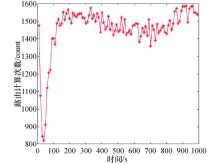
吞吐量如图10所示, 在不同的移动速率下, QL-OLSR的吞吐量明显更高, 在单位时间内成功传送数据的数量增多.在节点不移动的情况下, 受链路速率影响, QL-OLSR的吞吐量更高但是基本变化不大; 而当节点移动速率为10 m/s时, 会更加明显, 这也说明了QL-OLSR相比OLSR路由协议在节点的移动速率变化的情况下, 要更加适应网络的拓扑变化.图11中可以得到在仿真时间为700 s左右的时候, 路由计算次数基本保持一致.
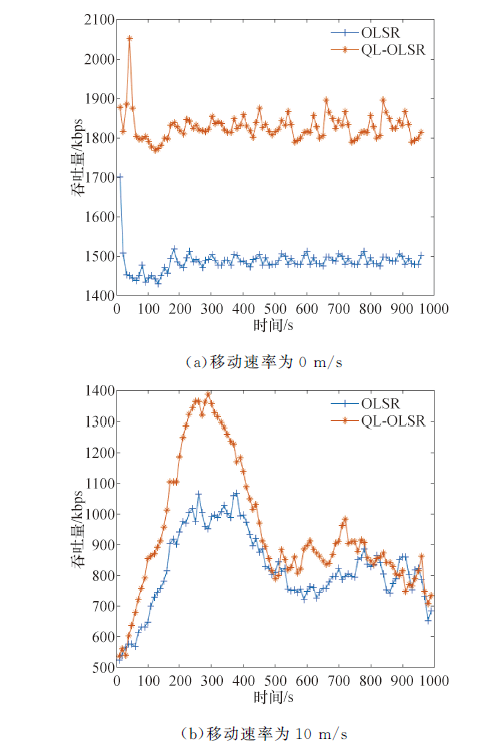 | 图10 吞吐量结果对比Fig.10 Throughout comparisons |
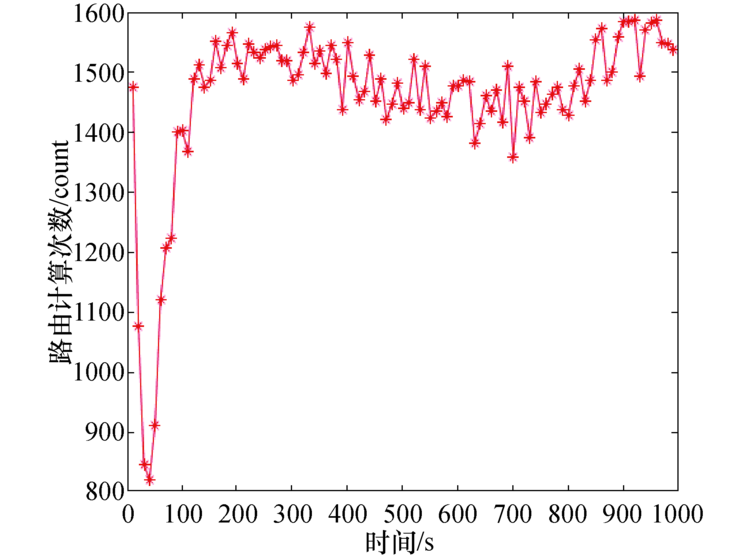 | 图11 路由计算次数Fig.11 Routing calculate time |
综上可得, 在网络拓扑变化快的场景中, OLSR协议的路由在建立的过程中, 由于节点的移动速度过快, 导致节点建立路由的时间更长, 所以端到端延迟更大; 而QL-OLSR中采用了Q-Learning的思想, 网络会选择链路容量高的路由, 在保证节点稳定性的情况下建立合适的路由, 从而保证了网络有更好的性能、更低的时延、更高的吞吐量.
1) 基于Q-Learning思想后的路由策略加入OLSR路由协议中后, 更加适用于高速移动、节点移动性快的移动自组网场景.
2)相比传统的OLSR路由协议, 改进后的QL-OLSR路由协议在端到端延迟、时延抖动、业务接收量等方面有明显的优势.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|