{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于随机矩阵理论的大规模MIMO系统窃听用户检测
[刘铭1  , 徐丽
, 徐丽1 , 王晓懿2 , 陈佳奇3 ]
, 徐丽|
|


第一作者:刘铭(1982—),男,陕西西安人,副教授,博士,博士生导师.研究方向为5G/B5G移动网络、物理层安全.email:mingliu@bjtu.edu.cn.
针对传统的利用信息论准则检测主动窃听用户方法的弊端,提出了适用于样本数目小于基站天线数目的检测主动窃听用户的算法.通过将线性收缩方法和子空间方法结合,有效地在小样本场景下进行主动窃听用户检测,而不产生额外的计算开销.提出利用大维随机矩阵理论获得对噪声方差更为精确的估计.同时采用线性收缩方法对样本协方差矩阵的特征值进行线性收缩,使其更好地拟合总体协方差矩阵,以提升小样本情况下的检测性能.最后利用子空间方法对线性收缩后的样本特征值进行检测,准确地检测是否存在主动窃听用户.蒙特卡洛仿真结果表明,结合大维随机矩阵理论与线性收缩的检测算法可以在小样本场景中有效检测主动窃听用户.
According to the traditional method of using information theoretic approach to detect active eavesdropper, this paper proposes an algorithm for detecting active eavesdropper with a sample number smaller than the number of base station antennas. The proposed method combines the linear shrinkage method with the subspace method, and can detect active eavesdropper effectively when the number of samples is not large, without a significant increase of computational overhead. Specifically it proposes to employ the large-dimensional random matrix theory to obtain a more accurate estimate of noise variance. Linear shrinkage method is adopted to process the sample covariance matrix such that it can better fit the population covariance matrix and yield a better detection performance when the number of samples is not large. With the assistance of linearly shrinked sample covariance matrix, the subspace method is used to determine whether there exists active eavesdropper. The Monte Carlo simulation results show that the combination of large-dimensional random matrix theory and linear shrinkage detection algorithm can effectively detect the existence of the active eavesdropper when the number of samples is not large.
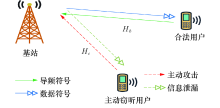
大规模MIMO(Massive Multiple-Input Multiple-Output)技术作为第五代移动通信网络(5G)的物理层关键技术, 具有前所未有的数据速率、频谱效率、能量效率、网络容量及更高的链路可靠性和覆盖范围[1].然而, 因为无线通信环境的开放性, 大规模MIMO也存在一定的安全风险.大规模MIMO系统需要利用合法用户发送的导频信息估计下行信道的状态.在此过程中, 恶意用户可通过发送与合法用户相同的导频序列, 来误导基站的信道估计过程, 将下行链路信号波束引导到恶意用户的位置, 从而达到窃听的目的.该行为也被称为主动窃听攻击[2].主动窃听攻击会严重地影响到无线通信环境的安全, 它将会阻塞合法用户的上行传输, 同时造成下行合法用户信息的泄漏[3, 4, 5].因此, 有必要研究适用于大规模MIMO系统的检测主动窃听攻击方法.
2012年, 文献[6]指出了采用时分双工(Time Division Duplex, TDD)体制的无线通信系统中可能存在主动窃听攻击问题.针对此问题, 不同研究者展开了一系列的相关研究.如:基于随机序列的检测算法[7].基于信道统计的检测算法[8]基于传输功率的检测算法[9]和基于信号子空间的检测算法[10].
现有的窃听用户检测算法大多是基于信息论准则进行窃听检测, 可以在用户单天线场景中有效地检测窃听用户, 但是在实际的用户多天线场景中检测性能较低.一般来说, 基于信息论准则的方法需要考虑样本特征值的分布.利用特征值分解(Eigen Value Decomposition, EVD)将样本协方差矩阵分解为信号子空间和噪声子空间.大的特征值对应的特征空间为信号空间, 小的特征值对应的特征空间为噪声空间.当基站天线数量保持固定而样本数量趋于无穷时, 该方法性能达到最佳.而在当基站天线数量大于样本数量的高维信号场景中, 信息理论准则方法的性能会严重恶化, 检测性能欠佳.
基于信号子空间的方法可较好地检测到主动窃听用户的存在.现有的基于信号子空间方法大多是当基站天线数量保持固定而样本数量趋于无穷时, 算法检测性能才能达到最佳.但是由于系统效率和成本的限制, 使用更小的样本进行窃听用户检测, 可带来更低的信号传输开销、时延和复杂度, 所以需要研究小样本场景下的主动窃听检测算法.而当样本数量小于基站天线数量, 即小样本场景时, 子空间算法的性能会严重恶化[11].在经典情况下, 基站天线数目是固定的, 样本数趋于一个较大值, 样本协方差矩阵的特征值是总体协方差矩阵特征值的良好估计.因此, 在子空间方法中, 使用样本协方差矩阵的特征值, 可替代总体协方差矩阵的特征值.而对于高维问题, 矩阵的维度比样本的数量更大, 此时样本协方差矩阵的特征值不再是总体协方差矩阵特征值的良好估计.所以在小样本场景下使用子空间方法进行窃听用户检测时需要对样本协方差矩阵进行修正.
本文作者针对样本数小于基站天线数目的场景, 将大维随机矩阵理论(Random Matrix Theory, RMT)和线性收缩(Linear Shrinkage, LS)的方法相结合, 提出了一种基于大维随机矩阵理论-线性收缩(RMT-LS)的子空间窃听用户检测算法.
本文中基站Alice和合法用户Bob工作在TDD模式下.假设大规模MIMO系统中存在主动窃听用户Eve.其中基站Alice具有几十至数百个(
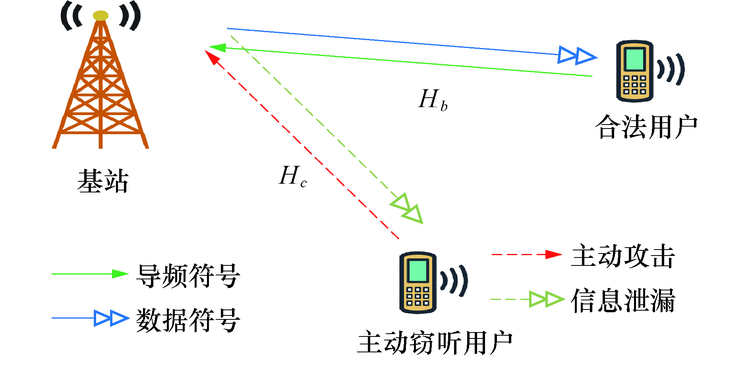 | 图1 通信系统中主动窃听行为示意Fig.1 An illustration of active eavesdropping in massive MIMO-based systems |
基于随机序列的主动窃听检测方法, 在训练序列之后发送一系列随机序列.Alice收到的来自Bob的随机序列表示为
当Eve对Bob所发送的随机序列施加污染时, Alice收到的随机序列可表示为
式中:
以矩阵形式重写式(1)和式(2)可得
式中:
令
式中:
接收信号也是独立且同分布的复高斯随机向量, 即
经典的MDL(Minimum Description Length)检测算法可以表示为[14]
式中:
基于子空间的窃听检测算法思想是找到最小的
利用Ledoit和Wolf(LW)方法求解线性收缩系数[15], 求得噪声子空间的样本协方差矩阵的线性估计, 过程如下
式中:
式中:
LW方法给出了式(9)中存在的收缩系数为
由于
式中:
通过将噪声子空间的样本特征值收缩到噪声方差, 进而得到优化后的样本协方差矩阵的特征值.
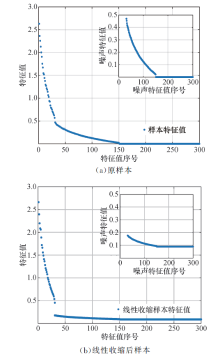
图2展示了本文算法对噪声子空间样本特征值的影响程度(
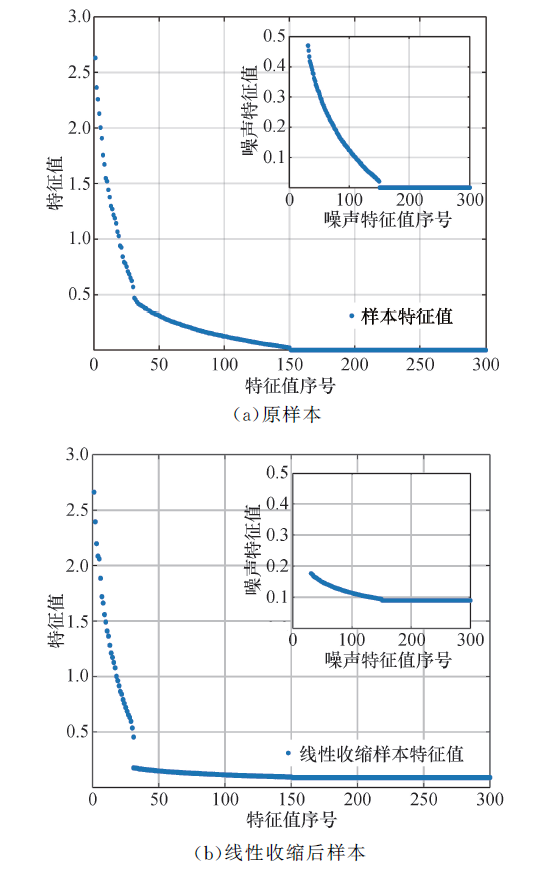 | 图2 协方差矩阵的特征值分布Fig.2 Distribution of eigenvalues covariance matrix |
在小样本的场景下, 噪声子空间的样本特征值散布的空间较大, 偏离了真实噪声特征值的分布范围, 即偏离了真实的噪声方差.本文对噪声子空间的样本协方差矩阵进行线性收缩, 使得样本协方差矩阵得到的噪声子空间的特征值向其真实的噪声方差趋近.图2(a)中噪声特征值偏离真实噪声方差(0.1)较远.而图2(b)中线性收缩后的噪声特征值在其真实方差(0.1)附近波动.说明线性收缩程度较好, 收缩后的样本特征值更能拟合真实的特征值分布.
线性收缩方法中比较重要的一个环节是进行噪声方差估计, 传统的噪声估计方法[14]中
传统的噪声估计方法首先对接收信号矩阵的特征值进行降序排序, 随后对排序后特征值序列的后
首先, 定义基站接收的随机序列为
定理1[16]:定义样本协方差矩阵
式中:r表示合法用户, r=1, 2, …, L;
举例说明
即
对于估计方法中存在的
式(16)表示存在多个合法用户时信号功率的估计.考虑只存在一个合法用户, 即
式中:
以上是根据大维RMT中Stieltjes变换推导得到的
式中:
证明:定义
对积分进行离散化, 得到
式中:
当只存在一个合法用户, 即
本节将大维RMT与线性收缩样本特征值的方法相结合, 设计了窃听用户检测算法.将式(14)中求得的线性收缩后的特征值带入MDL算法式(7)中, 并改变其惩罚项, 得到重新定义后的MDL算法为
式中:
通过最小化式(31)得到窃听用户检测算法的检验统计量
根据式(31)中得到的检验统计量, 将假设式(5)和式(6)重新表述为
在假设检验中, 如果
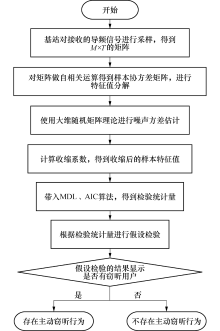
大维RMT与线性收缩方法相结合的子空间窃听用户检测算法具体实施步骤, 如图3所示.
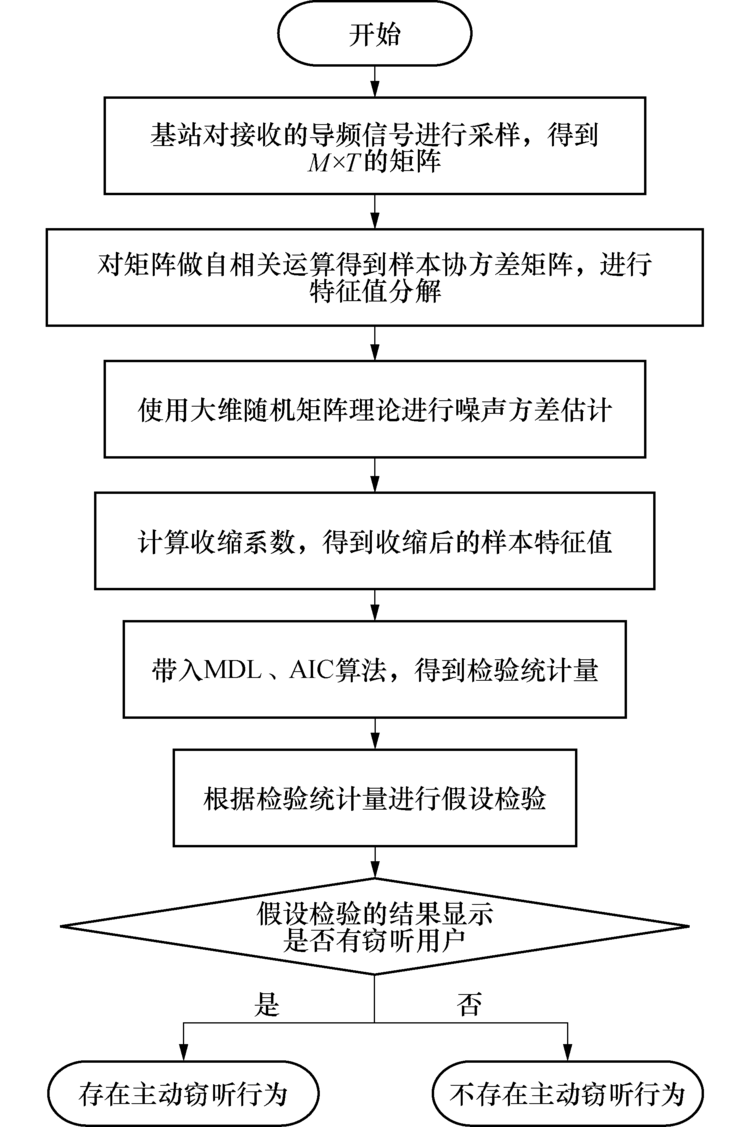 | 图3 主动窃听检测算法流程Fig.3 Flow chart of the active eavesdropper detection |
本节对式(31)提出的基于大维RMT-LS的子空间检测算法进行仿真实验, 展示了在不同天线数目、样本数、信号功率和信噪比环境下算法的检测性能曲线.并在最后仿真了基于大维RMT进行参数估计的算法和传统的参数估计方法对窃听检测的影响.对于每一次仿真实现, 信道系数服从复高斯分布, 其均值为0, 方差为1.加性白噪声服从复高斯分布, 其均值为0, 方差为
仿真实验中根据检测概率和虚警概率评估算法性能.检测概率表示系统存在窃听用户时, 检测算法能够检测到窃听用户的概率.虚警概率表示系统中不存在窃听用户时, 检测算法错误地检测到窃听用户的概率.因此, 高检测概率和低虚警概率是检测算法的期望目标.
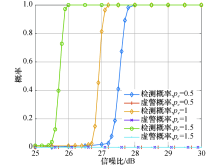
图4展示了在不同的主动窃听用户与合法用户信号功率比值(
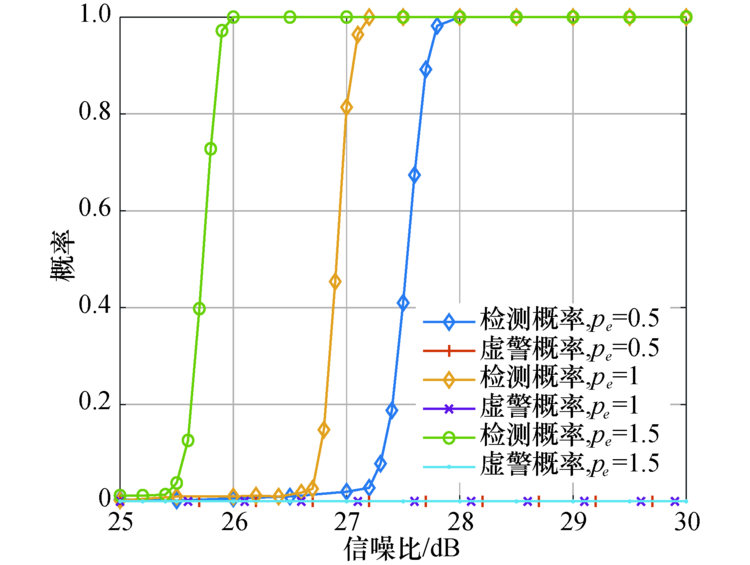 | 图4 功率和合法用户信号功率对算法检测性能的影响Fig.4 Effect of eavesdropper’ s signal and legitimate user’ s signal power on detection performance |
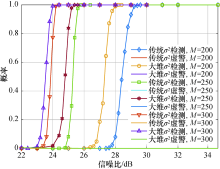
图5展示了在不同的天线数目
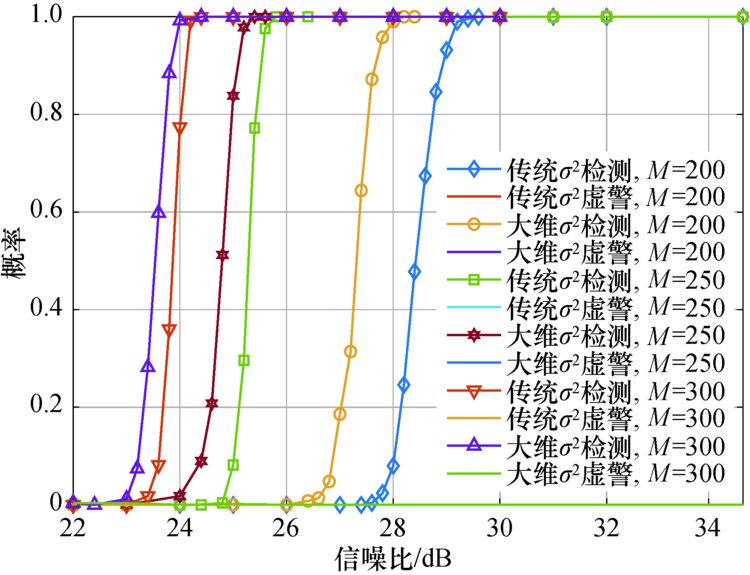 | 图5 基站天线数目对不同算法检测性能的影响Fig.5 Effect of the number of base station antennas on detection performance of different algorithms |
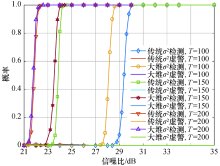
图6展示了在不同样本数
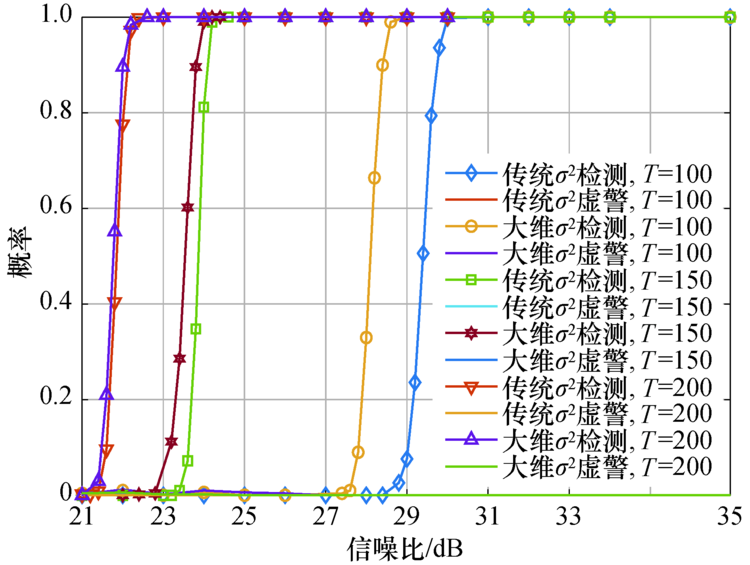 | 图6 样本数对不同算法检测性能的影响Fig.6 Effect of the sample number on detection performance of different algorithms |
可以得出:算法检测概率随着SNR增加而上升, 直到趋向于1.当样本数从100增加到150时, 检测性能约改善4.5 dB.即当基站天线数固定时, 检测概率随着“ 天线-采样比” 的减少而增加, 虚警概率趋近于零.在样本数小于基站天线数时, 增加样本数, 算法的检测性能随之增强.对比发现, 随着信噪比和样本数目的增加, 两种算法的检测性能都随之增强.
1)提出一种基于大维RMT-线性收缩的主动窃听用户检测算法.利用大维RMT, 对特征值的分布函数进行Stieltjes变换, 求得噪声方差的估计值.
2)将估计得到的噪声方差用于线性收缩方法, 收缩样本特征值, 使其更好地拟合总体特征值.再次, 利用线性收缩算法得到噪声子空间分量的协方差矩阵的精确估计, 将线性收缩后的噪声特征值用于传统的信息论准则算法, 从而得到检验统计量进行假设检验.
3)对基于大维RMT-线性收缩用于窃听用户检测的算法进行蒙特卡洛仿真, 实验结果表明算法具有较高的检测概率和较低的虚警概率.
4)算法在小样本场景下可以达到有效检测窃听用户的效果.并且检测性能随着样本数、基站天线数目和信号功率的增加得到改善显著.同时, 算法可以适用于多种传统的基于子空间方法的窃听用户检测, 拓展了算法的应用场景.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|