
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合二次特征提取和LSTM-Autoencoder的网络流量异常检测方法
[孙旭日1  , 刘明峰
, 刘明峰1 , 程辉1 , 彭博1 , 赵宇飞2 ]
, 刘明峰|
|


第一作者:孙旭日(1967—),男,山东莱阳人,高级工程师.研究方向为电力信息通信技术及信息安全技术.email:sunxuri165@163.com
为解决大多数网络流量异常检测方法准确度低、误报率高等问题,提出一种基于长短期记忆网络自编码(LSTM-Autoencoder)的网络流量异常检测方法.首先,将真实网络流量从数据包和会话流级别两方面提取数据特征.为了丰富原始特征,采用离散小波变换(DWT)分解原始特征向量得到更高维特征.考虑真实网络环境可能存在异常数据,采用Grubbs 准则对数据进行平滑操作,以防止非人为异常数据干扰训练LSTM-Autoencoder模型.使用已训练的LSTM-Autoencoder模型对训练数据进行重构,通过分析重构误差分布确定检测阈值.最后,对真实网络流量进行测试,分析了模型结构以及外部噪声对检测性能的影响,实验结果验证了所提方法的正确性.与其他基于数据重构的检测方法相比,所提方法具有更高的检测准确度和更优的检测性能.
In order to solve the problem of low detection accuracy and high false positive rate in anomaly detection. A Long Short Term Memory (LSTM) based anomaly detection method is proposed. First, the features are extracted from data packages and the session flows. To enrich the data features, the Discrete Wavelet Transform (DWT) technique is used to decompose the original data into the feature vectors with higher dimension. Considering the non-human abnormal data in the real network environment, the Grubbs Criterion is used to eliminate the non-human abnormal data in case of disturbing modeling LSTM-Autoencoder. Then, the reconstruction errors of input feature vectors are calculated by the LSTM-Autoencoder model. The distribution of the reconstruction errors is fitted and the detection threshold is determined. At last, the experiments are conducted on the real network data. The influences of the model structure and the environment noise on the detection performance are analyzed. The experimental results verified the feasibility of the proposed method and shown that the proposed method can effectively identify the abnormal data and has a better performance in detection accuracy compared with other detection methods.
异常流量检测作为网络安全领域的重要组成部分, 成为学术和工业界的研究热点.它主要通过分析目标系统中的数据流量来检测异常行为[1].传统的检测方法集成了数据采集、分析、可视化等功能以实现对网络流量在空间上的监控.目前广泛使用的入侵检测系统(IDS)和入侵防御系统(IPS)等作为网络流量检测的合理补充, 虽然在一定程度上实现了网络异常流量的精准识别, 但存在误报率或漏报率高的问题[2, 3, 4].
现存的网络异常流量检测方法可分为基于规则的检测和基于误用的检测[5].针对基于规则的检测, 文献[6]通过建立能够区分正常和异常流量的规则, 判断输入流量是否满足预设规则从而达到检测异常流量的目的, 这类方法的检测准确度较高, 但普遍存在误报率高的现象.文献[7]通过分析流量分布并设置评判流量归类阈值以检测网络中的异常流量, 虽然这种方法实现简单, 但使用的方式固定, 难以适应多种动态变化的网络流量数据, 且该方法性能对外部噪声敏感, 因此鲁棒性较差.基于误用的检测方法, 即统计现有流量在空间或时间上的特征, 将网络流量异常检测视为二分类问题, 并结合机器学习算法实现对异常流量的检测, 如ORCA[8], LOF[9]通过分析正常和异常流量的时间相关性挖掘流量特征, 使用时间序列数据预测方法预测下一时间点网络流量是否正常, 但这两种方法使用了具有周期性强的时间序列数据, 在建模过程中需存储高维特征数据, 这无疑加大了系统的检测成本.
此外, 文献[8]提出了一种基于网络流量空间特征的检测方法, 即通过计算被检测的流量特征和预测值分布之间的Kullback-Leibler 距离实现网络流量异常检测, 但该方法的检测准确率不高, 鲁棒性较差.文献[10]将单位时间内的网络流量拟合为多维参数向量, 再利用支持向量机算法对网络流量特征向量进行分类, 显然经拟合产生的特征向量无法全面表征网络流量, 导致检测精度偏低.因此, 有必要提出一种准确率高、误报率低的自动化检测方法.
为保障所提方法实际可用, 本文作者首先对实际的网络流量进行分析, 从数据包级别和会话流级别两方面提取流量特征[11, 12].此外, 为了克服人为选定特征的主观性并丰富数据特征, 使用离散小波变换(Discrete Wavelet Transform, DWT)对原始特征向量进行二次特征提取重新组成较高维的特征向量.将正常的高维特征向量作为时间序列数据输入到基于长短期记忆网络(Long Short Term Memory, LSTM)的自编码网络 (LSTM-Autoencoder) 中进行模型训练.最后, 通过计算训练数据集经LSTM-Autoencoder处理后产生的重构误差, 并根据误差分布设定检测阈值实现对测试数据集的检测.在训练LSTM-Autoencoder网络前, 为了防止训练数据集存在非人为产生的异常数据而干扰模型训练, 采用Grubbs Criterion对特征向量进行预处理以排除训练集中的异常数据.
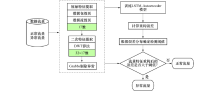
本文所提的基于LSTM-Autoencoder的网络流量异常检测模型实现过程如下:
1)通过采集实际网络流量, 从数据包级别和会话流级别提取多维特征以表征特定时间段内的网络流量数据.
2)为了更全面表征数据流量特征, 克服人为选定特征的主观性, 采用DWT对原始特征向量进行分解重新组成更高维特征向量.
3)将重新生成的高维特征向量分为训练和测试数据集以便后续模型训练, 并对测试数据集和训练数据集进行归一化操作.其中训练数据集只含有正常的网络流量特征向量.
4)使用处理后的数据集训练LSTM-Autoencoder模型, 并将训练集数据重新输入到训练好的模型中, 统计数据的重构误差分布以确定检测阈值.
5)将测试数据集输入到训练好的LSTM-Autoencoder模型中, 计算数据的重构误差并与设定阈值进行比较, 最终实现异常流量识别.
图1为所提的流量异常检测方法的实现流程.
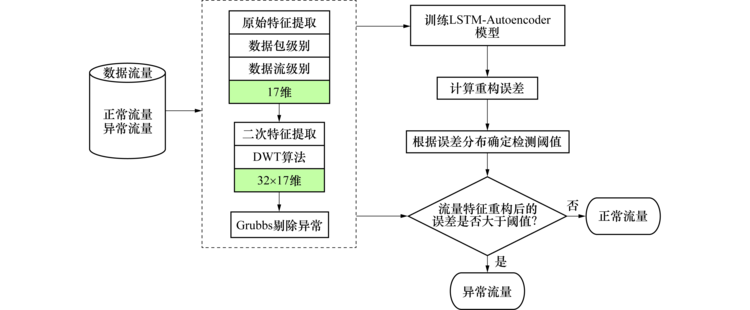 | 图1 实现流程图Fig.1 Schematic of the detecting model |
通过对实际网络环境的流量分析可发现基于TCP协议的数据包是整个流量的主要部分.一个完整的TCP会话包括“ 3次握手” 和“ 4次挥手” 过程, 实际中也会存在连接超时的情况, 设定超时时间为T, 若在T内没有任何数据包, 则会话流结束.现存的常见攻击如APT、 DoS、 Land、 SYN flood也主要针对TCP.不失一般性, 本文主要考虑数据流量中的TCP数据特征, 从数据包和会话流两方面提取流量数据特征.在包长度、端口、速度类、地址类、分布类等方面构造了流量特征.
根据数据包的流向, 攻击者往往向主机发送异常流量达到攻击的目的, 因此, 围绕下行数据包, 下行流量特点和数据接收数据特点进行特征提取更具实际意义, 设观测时间段为t, 则N个时间段对应的流量特征可表示为F1, F2, … FN.单个特征向量FN内含有的特征元素定义见表1.
| 表1 特征列表 Tab.1 Features list |
1.1节通过人工分析从包级别和会话流级别两方面定义了17种数据特征, 虽然可以基本区分出正常流量和异常流量间的差异, 但这些特征是基于人工定义分析获得, 因此具有主观性强的特点.本节采用信号处理方法DWT对原始特征进行分解, 提取原始特征向量中的隐藏时频特征[13], 以更全面深层次地表征数据流量.
DWT可使用预定义的母小波派生出零均值函数, 并将此均值函数重新作为小波以实现对原始特征数据序列的卷积操作.通常, 根据母小波φ (t)展开为
φ a, b(t)=
式中:a和b分别是缩放和位移参数.通过a = 2j和b = 2j× k(j, k为实数), 进行离散化.使用该离散小波函数可将原始输入信号s(t)转换为
式中:
式中:aM, k和φ (t)分别是级别为M和缩放函数的近似系数.根据式(3), 不难发现, 可将原始信号s(t)分解为近似系数AM(t)和关于M的详细系数Dj(t)间的函数关系[14].从式(2)和式(3)可以看出, 不同的小波和分解级别M可导致不同的分解信号系数.这些系数将直接影响DWT特征提取结果.虽然应存在最佳子波和最佳级别M, 但是一一测试所有子波不切实际.当数据集包含足够的信号样本时, 小波函数的鲁棒性与特殊数据属性无关.本文首选db和sym族小波, 其他小波族如bior和coif具有较长的滤波长度, 具有分解级别低和特征提取能力差的缺点.所选小波及其各自对应的M值见表2.
| 表2 小波种类及分解级别 Tab.2 Feature extraction wavelets and decomposition levels |
根据式(3), 一个输入信号可分解为16个信号系数向量. 但是, 分解后的系数向量较长, 无法在后续计算中使用. 因此, 使用这些数据向量的统计特征代表原始输入向量的关键特征.即采用系数向量中元素的平均值和标准差来表示原始输入信号.如图2所示, 以分解级别M=4为例展示DWT提取分解系数过程, 其中Cd1~Cd4和Ca4为分解子信号的系数.DWT提取特征通过对输入原始信号进行分解扩展特征向量可实现对原始输入信号的更深层次特征挖掘.则新的特征向量共含16(系数)× 2(均值和标准差)× D(原始特征向量维度) = 32D, 其中D为17.
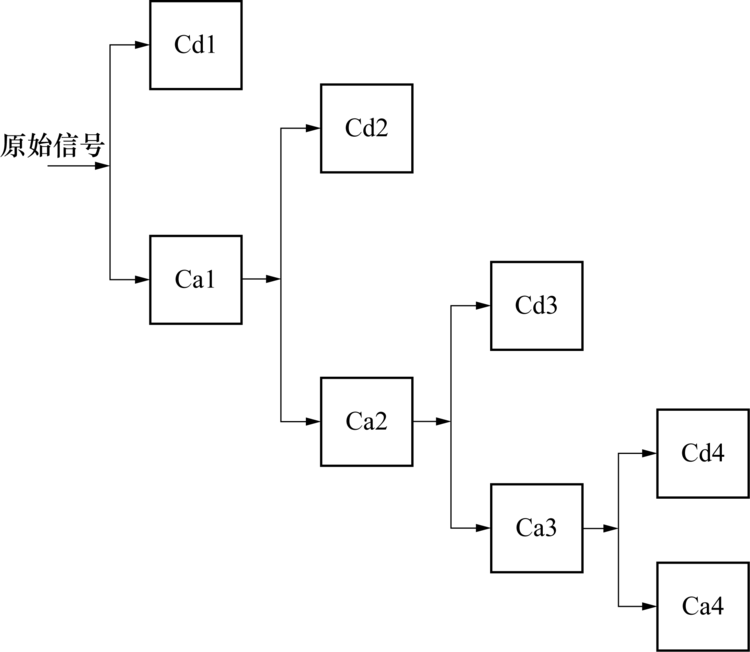 | 图2 DWT4层分解示例Fig.2 An example of DWT4-decomposition |
正常网络环境中, 由于数据采集端的异常往往会产生除正常流量和攻击流量外的非人为异常流量, 这些流量虽然不会对网络系统产生实质威胁, 但会影响后续算法模型的构建.因此, 本文使用Grubbs Criterion对网络流量进行适当预处理, 平滑掉异常数据[15].
Grubbs Criterion作为判断数据粗大误差的一种准则, 可以用于异常数据处理领域.本文使用该方法的具体流程是, 首先将一周内不同工作日相同时间段内的流量特征数据表示为Xi, 其中i=1, 2, 3, 4, 5.则不同工作日、相同时间段的数据共5个, 可表示为X1~X5, 其均值和方差表示为
如果Xi满足|Xi-
1) 如果标准差大于2倍均值, 则剔除距离均值最大的值, 重新计算均值和标准差.
2) 每次循环只剔除一个异常值, 下一次重新计算均值、标准差, 直到所有的值都满足判别公式.
经异常数据剔除操作后, 将特征向量中的每个属性值都进行线性归一化, 最终将属性映射到0到1之间.
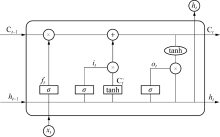
LSTM作为一种特殊的循环神经网络(Recurrent Neural Network, RNN)可以学习长期数据依赖信息.解决了循环神经网络的梯度消失和梯度爆炸问题[16, 17].每一个LSTM网络单元主要由遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)和一个记忆单元(Cell)构成, 通过3种门结构和记忆单元协同工作, LSTM可以对输入信息进行长期记忆、更新和筛选.在 LSTM网络模型中, Cell 可记录神经元单元的状态, 通过设定一个名为 state 的参数表示状态, 输入门和输出门则分别用来接收和输出参数, 遗忘门可将不符合算法验证的信息丢弃.LSTM的结构原理如图3所示.各个门结构在LSTM网络中的具体功能为:
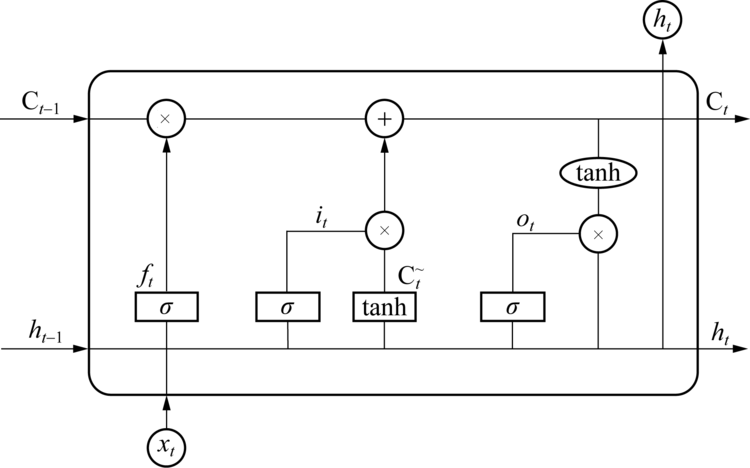 | 图3 LSTM神经网络结构Fig.3 Structuctre of LSTM neural network |
1) 输入门.作用是控制哪些信息被放入细胞状态值中, 其数学模型为
在进行输出之前, LSTM会确定更新的信息, 决定丢弃哪些旧状态的信息, 即
2) 遗忘门.作用是决定从细胞状态Cell中丢弃什么信息, 其数学模型为
3) 输出门.作用是控制信息输出, 其数学模型为
式中:ft, it, ot分别为遗忘门、输入门、输出门, a, tanh为Sigmoid激活函数, 函数取值在[0, 1]; xt为t时刻的输入, ht为t时刻的输出, Ci和Cm为t时刻LSTM细胞状态和备选细胞状态; Wf, Wi, Wc, Wo和bf, bi, bc, bo为计算过程中所需的权重及对应的偏执.
由于LSTM具有长期记忆功能, 可有效应用于时间序列数据分析领域, 将过去的信息进行筛选并与当前信息进行结合从而实现预测功能.在LSTM模型的训练过程中, 为了保证模型达到最高的预测精度, 需通过计算预测值和实际值之间的重构误差进行参数调节.基于LSTM可用于准确预测未来信息的能力, 本文提出一种基于LSTM的Autoen深度学习网络结构重构输入数据, 通过判断数据重构误差实现网络流量异常检测.
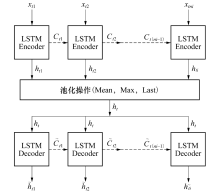
LSTM-Autoencoder分为LSTM-Encoder和LSTM-Decoder两部分, 前者对输入的特征向量时间序列数据进行等长学习表达, 后者使用当前的隐含状态和前一步预测的值对Encode后的时间序列进行重构.设输入数据序列X1, X2, …, XN可定义为{Xi
式中: h(t-1)i∈ Rm为t-1时刻第i个编码单元的输出状态向量; xti∈ Rm为输入向量; W, R为m× d和m× m阶系数权重矩阵; 函数k(· )通常设为“ tanh” 激活函数并逐点应用到向量中.通过将Xi中的每个列向量输入到Encoder部分, 可得到输出为
式中:hti为t时刻第i个编码单元的输出; φ 为编码部分的参数集合;
式中:j为hit的行数, 经过池化操作后, hi输入Decoder部分后, 可将输入重构为
式中:
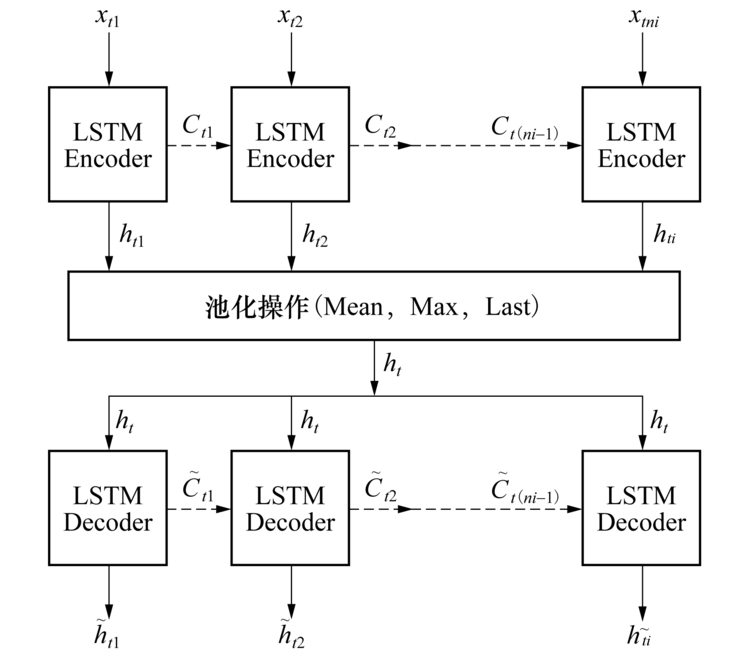 | 图4 LSTM-Autoencoder网络结构Fig.4 Structure of LSTM-Autoencoder |
将2中定义的LSTM网络结构应用到2中的Autoencoder结构中, 便可得到LSTM-Autoencoder结构, LSTM-Autoencoder结构中的Encoder和Decoder定义为
经上述分析, 每个特征向量数据输入LSTM-Autoencoder后都会产生对应的输出, 根据输入和输出可计算出重构误差.对于正常的特征数据, 其经过LSTM-Autoencoder处理后的重构误差往往小于异常数据对应的重构误差.使用正常流量训练LSTM-Autoencoder模型, 计算输入数据与输出数据之间的重构误差, 当异常流量输入训练好的模型时, 其重构误差会高于正常流量对应的重构误差.通过统计正常流量经模型计算的重构误差的分布确定检测阈值τ , 当新输入数据的重构误差大于该阈值时则可认为该数据为异常.定义特征向量数据序列Xt=[xi1, xi2, xin]的重构误差为
由于最终的E(t)在LSTM-Autoencoder模型训练中确定, 该误差值不仅可以作为Encoder部分和Decoder部分更新权重的标准, 其值的分布是本文后续设定检测阈值的基础.
为验证所提方法的有效性, 本文采集国家电网某省内部服务器流量作为实验数据.实验中连续采集了4周无异常日志报警流量, 向第4周流量数据通过手工注入攻击payload的方式模拟攻击者从而产生异常流量.以1 min作为流量采集窗口, 因此4周共有40 320个时间段对应40 320个流量数据特征.其中异常流量含6 995条, 按正常流量与异常流量1:1的比例组成测试数据集, 则测试数据集共含13 990条流量特征数据.剩余的26 330条数据均为正常流量数据, 这些正常流量用于训练LSTM-Autoencoder模型, 并确定最优检测阈值.表3为测试集中异常流量数据中所含的攻击种类.
| 表3 测试数据集中异常流量组成 Tab.3 Constitution of abnormal data flows in testing set |
本文的实验仿真环境为:Windows 7 x64, 32 GB RAM, i7-7700 CPU, wireshark 2.4.5[18], Python 3.7[19], 不使用GPU加速.设置LSTM-Autoencoder 模型的训练次数为200次.首先, 本文测试了LSTM-Autoencoder用于数据重构的可行性, 通过计算重构后数据与原始数据之间的平均绝对误差(Mean Absolute Error, MAE)作为衡量LSTM-Autoencoder在数据重构方面优势.MAE的定义如下
式中:yd表示原始数据; yr表示重构的样本; N表示训练样本或测试样本的数量.
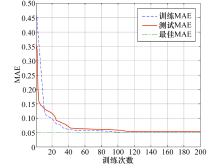
试验使用的LSTM-Autoencoder结构的隐含层由一层Encoder和一层Decoder组成, 输入层节点数与输入的特征向量维度相同, Encoder和Decoder节点数为输入层节点数的一半.图5为基于训练数据集和测试训练集中正常流量特征数据的MAE, 从图5中不难发现LSTM-Autoencoder在训练次数为120左右时逐渐收敛, 最终MAE达到0.049 5.这说明LSTM-Autoencoder能有效重构出本文所涉及的数据, 同时重构数据与原始数据相比其差异不大, 能够保留原始输入向量包含的信息.
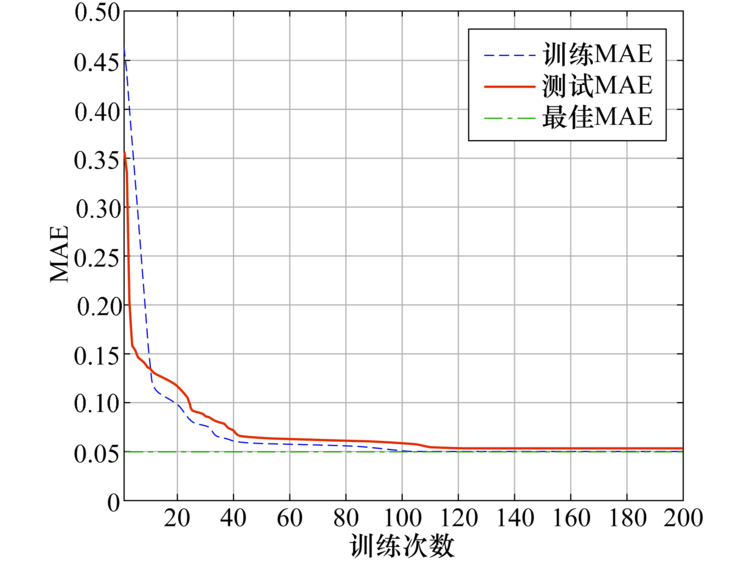 | 图5 LSTM-Autoencoder的重构误差变化曲线Fig.5 Reconstruction errors of LSTM-Autoencoder |
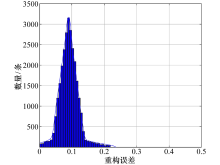
过大的阈值会导致检测准确率下降, 过小的阈值又会导致检测误报率较高.因此, 本文根据重构误差(式 (21))的分布设定阈值, 在统计完误差分布后, 使用曲线拟合误差分布, 将曲线与横轴的交点作为最优阈值.实验中, LSTM-Autoencoder结构采用上文所提结构, 观测窗口设置为5.如图6所示, 最优阈值选为0.236.将测试数据集输入训练好的LSTM-Autoencoder模型中, 计算每条数据对应的重构误差并与阈值相比进行流量检测, 实验结果如表4所示.
 | 图6 MAE的分布情况Fig.6 MAE distribution |
| 表4 检测准确度统计 Tab.4 Statistics of detection accuracy |
本文通过计算训练数据的重构误差来确定检测阈值, 且实验数据主要集中在一定的时间段内.为了验证所提方法的适用性, 本部分将对新的数据集进行测试分析, 新的数据集由训练数据集, 验证数据集和测试数据集三部分组成.其中新的训练数据集与上文所述的训练数据集保持一致, 从采集训练数据集的第10周开始采集测试数据集, 且数目与上文所提测试数据集保持一致.从采集训练数据集后的第4周开始采集10 000条正常数据作为验证数据集.通过统计验证数据集的重构误差分布, 检测阈值设置为0.271, 此时的检测结果如表5所示.
| 表5 基于验证数据集确定的阈值对应的检测效果 Tab.5 Detection performance based on the threshold determined by the new validation dataset |
从表4和表5可看出, 使用与训练数据时间相关性弱的验证数据可得到更大的检测阈值, 从而导致检测效果有所下降, 但仍能保证较好的检测效果, 此时的检测准确度为95.50%(对日常和异常的平均检测准确度).
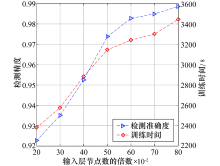
为分析LSTM-Autoencoder的结构对检测性能的影响, 通过改变隐含层节点数即Encoder和Decoder的节点数反映不同结构LSTM-Autoencoder的检测性能.设置Encoder和Decoder层所含节点数占输入层节点数的比例为c∈ [0.2, 0.8].实验采用5折交叉验证, 统计检测准确度和模型训练时间, 以及不同网络结构下的误报率和漏报率变化.如图7所示, 随着隐含层Encoder和Decoder中节点的增加, 检测准确度不断提升, 当c取0.6, 0.7, 0.8时检测准确度差异不明显, 但随着节点数的增加, 模型的构建时间大幅上升, 为平衡检测效果和模型的构建时间, 本文将c设置为0.6.
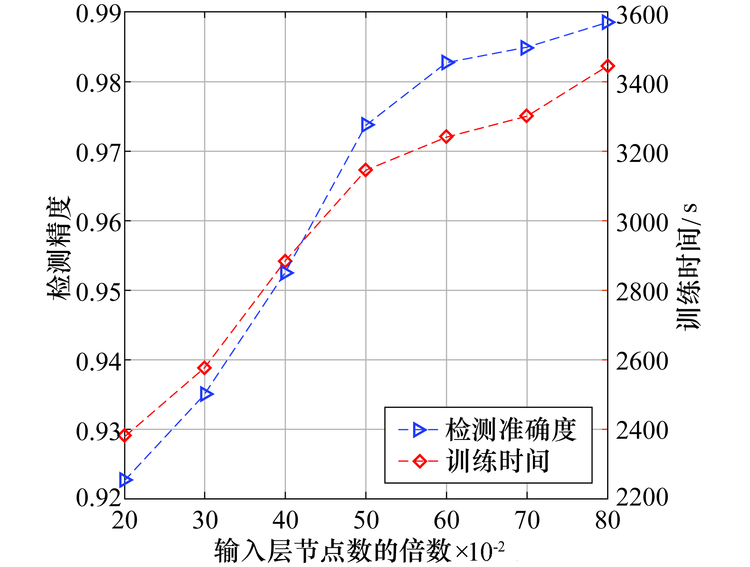 | 图7 不同隐层节点数下检测准确度和模型训练时间比较Fig.7 Comparison of detection accuracy and training time under different number of nodes |
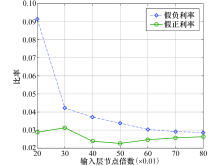
此外, 为了测试隐含层层数对检测效果的影响, 将LSTM-Autoencoder结构设置为输入-0.8× 输入-0.5× 输入-0.5× 输入-0.8× 输入-输出的双Encoder和双Decoder结构, 经测试, 采用双层编码和解码结构的检测准确度较3.1节使用的单Encoder和Decoder结构仅提高2%, 但随着隐含层的增加势必增加模型的训练时间, 这说明了本文采用单Encoder和单Decoder结构的正确性.定义误报率(False Positive Rate, FPR)和漏报率(False Negative Rate, FNR)为
式中:FP表示识别为异常但实际为正常的数量; TN表示识别为正常但实际为正常的数量; FN为识别为正常但实际为异常的数量; TP为识别为异常而实际为异常的数量.如图8所示的LSTM网络在不同节点数的单Encoder和单Decoder下的FPR和FNR, 可以看出针对本文采用的单Encoder和单Decoder结构, 当c=0.6时FPR和FNR小于4%.
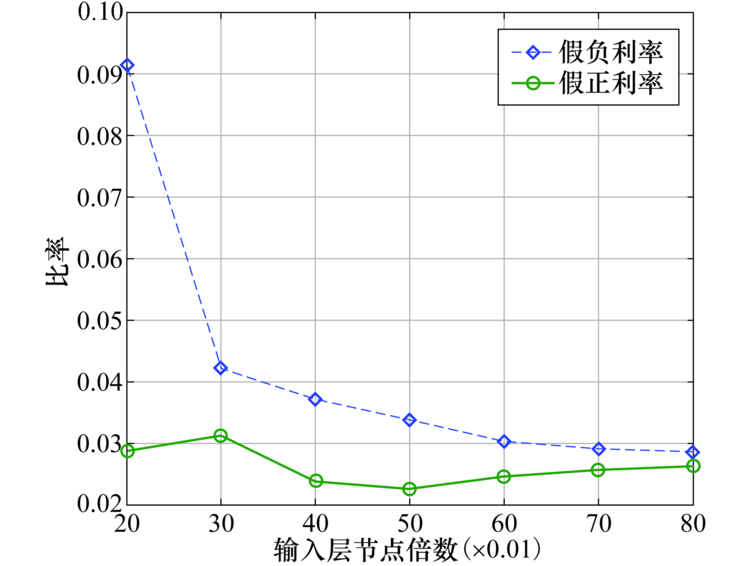 | 图8 不同隐层节点数下FPR和FNR变化Fig.8 Changes of FPR and FNR under different number of nodes |
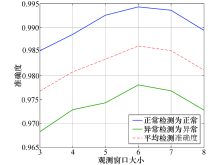
实验设置c=0.6, LSTM-Autoencoder结构采用单Encoder和单Decoder结构.观测窗口从{3, 4, 5, 6, 7, 8}中变化.如图9所示, 随着观测窗口增大, 所提方法的检测准确度不断提高.当观测窗口为6时准确度最高(98.74%), 之后检测准确度有所降低.这是因为随着观测窗口的增加导致一次性输入的数据包含了更多的信息, 而模型的隐含层节点数无法充分表征所有的特征从而导致检测准确度下降.此外, 本文所提模型采用Adam进行后向传播优化整个神经网络, 随着观测窗口的增大, 其后向传播速度会降低, 导致模型的训练时间增加, 综上分析, 观测窗口设置为6最为合适.
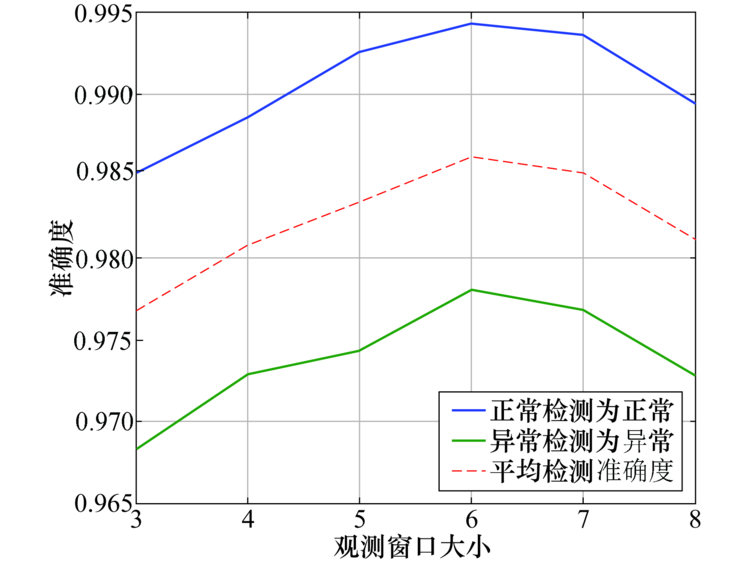 | 图9 不同观测窗口下检测准确度变化Fig.9 Detection accuracy under different observation window sizes |
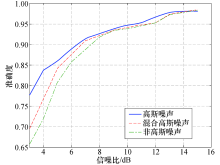
本文在噪声环境中测试所提方法的检测准确度以验证其鲁棒性, 在测试数据中分别加入高斯噪声、非高斯噪声和混合高斯噪声, 定义噪声e, LSTM-Autoencoder模型仍采用3.1中所用结构.通过调整信噪比控制加入噪声的大小, 从图10可以看出所提方法针对混有高斯噪声的测试数据检测效果最优, 针对混有混合高斯噪声的测试数据检测效果次之, 针对混有非高斯环境的测试数据检测效果最差.
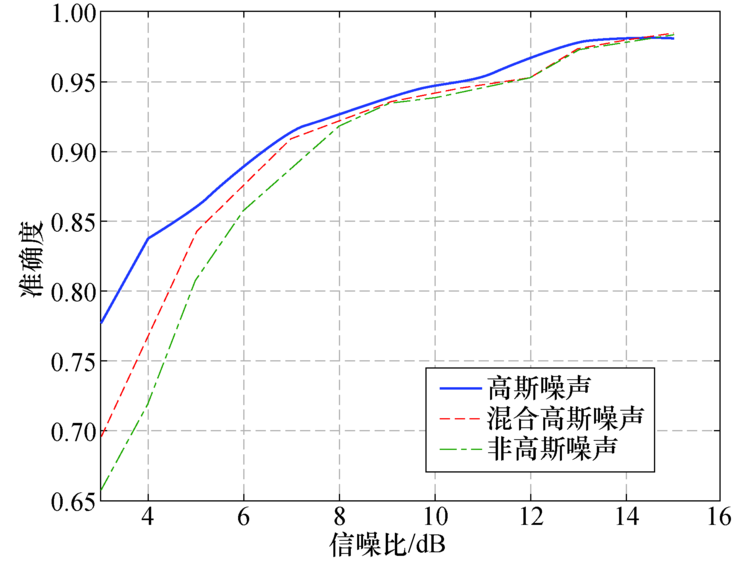 | 图10 不同种类噪声下的检测准确度Fig.10 Detection accuracy under different noise |
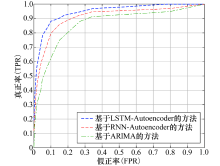
为了验证所提方法的综合优势, 本文与基于循环神经网络 (Recurrent Neural Network, RNN) 的Autoencoder[20]网络和基于ARIMA[21]算法的检测方法进行比较, 通过绘制ROC曲线验证所提方法的优势, 并计算曲线下面积 (Area Under Curve, AUC) 值来反映所提方法的优越性, 此时基于LSTM-Autoencoder的ROC曲线下的AUC值为0.986 4, 非常接近1, 且高于另外两种方法的对应的AUC值.这说明所提方法较另外两种方法具有更优的检测性能.
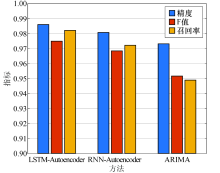
此外, 本文以F值, 精度和找回率作为指标评估所提方法的性能, 如图12所示, 所提方法在三个指标上均体现出明显优势.结合图11和图12可以看出, 本文所提方法的性能总体上优于基于RNN-Autoencoder和基于ARIMA算法的检测方法, 这主要是因为:1)基于LSTM的Autoencoder网络较基于RNN的Autoencoder网络能记录长期输入数据属性, 因此训练的模型能够表征数据包含的更多信息.2)ARIMA算法在处理时间序列数据时要求稳定的历史数据, 因此基于实际网络环境数据训练的模型检测能力一般.
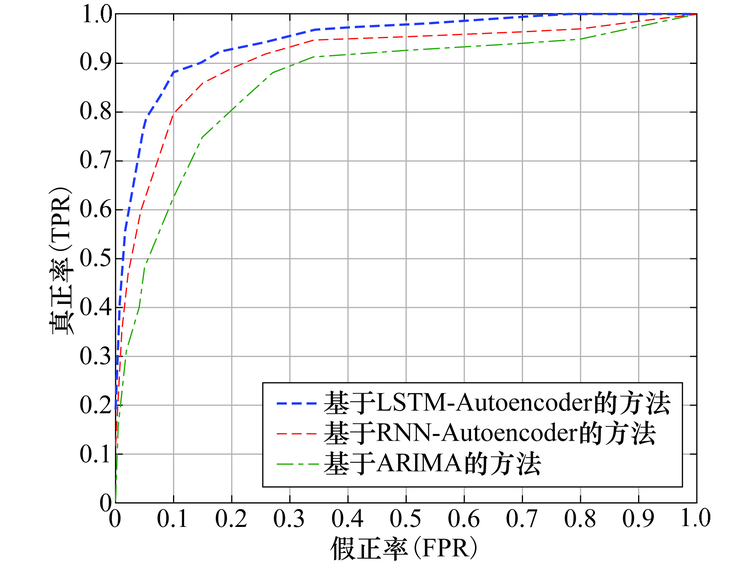 | 图11 不同方法的ROC曲线Fig.11 ROC curves of different methods |
 | 图12 综合性能统计Fig.12 Statistics of different evaluation indexes |
实验最后, 为验证DWT对原始特征进行二次提取的正确性, 使用原始特征数据和经过DWT处理重新生成的特征数据训练LSTM-Autoencoder模型, 表5统计了上文设定的检测评估指标, 可以看出, 基于经DWT分解后重组的特征向量训练的LSTM-Autoencoder模型具有更高准确度和更低的误检率, 且其整体性能优于基于原始特征训练的LSTM-Autoencoder模型.
1)提出一种基于LSTM的自编码网络并将其应用到网络流量异常检测中.通过分析实际网络环境中的流量, 从数据包级别和会话流级别出发定义多维流量特征.为了更全面表征数据流量, 采用离散小波变换对原始特征向量分解实现特征的第二次提取.使用Grubbs Criterion对数据进行平滑操作防止异常数据对后续模型训练产生干扰.使用训练好的LSTM-Autoencoder对特征向量进行重构, 通过统计重构误差分布确定检测阈值.
2)实验结果表明, 所提方法具有较高的检测准确度和更低的误报率, 与基于RNN的Autoencoder方法和基于ARIMA的方法相比, 所提方法具有更优的检测性能.
在今后的研究工作中, 重点开展对实时检测方法的研究.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|