

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种面向区块链的优化PBFT共识算法
[方维维1  , 王子岳
, 王子岳1 , 宋慧丽1 , 王云鹏1 , 丁毅2 ]
, 王子岳|
|


第一作者:方维维(1981—),男,安徽芜湖人,副教授,博士.研究方向为计算机网络.email:fangww@bjtu.edu.cn.
区块链技术具有去中心化,数据不可篡改和数据透明等特点,使得该技术的应用领域不断扩展,但目前应用于区块链系统的共识算法存在着资源浪费和共识效率较低等问题,限制了区块链技术的发展.针对此问题,基于实用拜占庭容错算法(Practical Byzantine Fault Tolerance,PBFT),算法的基本思想,提出了一种优化的共识算法.该算法引入积分机制,根据节点积分挑选参与共识的节点,以降低网络中的通信开销;在不存在拜占庭节点的情况下,优化PBFT算法的一致性协议;引入升降级机制,动态更新参与共识的节点集合,以保证算法在大部分时间内都执行优化一致性协议.实验结果表明: 与PBFT算法相比,本文提出的共识算法将共识过程的时间复杂度从
Blockchain technology has the characteristics of decentralization, data tamper-resistantand data transparency, which makes the application field of blockchain technology expand continuously.However, the consensus algorithm applied to the blockchain system currently has problems of resource waste and low efficiency, which limits the development of blockchain technology.Aiming at this problem, this paper proposes an optimized consensus algorithm based on the basic idea of PBFT(Practical Byzantine Fault Tolerance) algorithm. This algorithm introduces an integration mechanism to select nodes participating in the consensus based on node points to reduce communication overhead in the network, and optimizes the consistency protocol of the PBFT algorithm in the absence of Byzantine nodes. It also introduces a lifting level mechanism to dynamically update the nodes participating in the consensus process to ensure that the algorithm performs the optimized coherence protocol most of the time.The experiment results show that the new consensus algorithm reduces the time complexity of the consensus process from
区块链(Blockchain)是以比特币为主的数字加密货币的重要底层技术, 最早是在2008年由化名为中本聪的学者提出.他提出了一种不需要任何第三方金融机构参与, 由交易双方直接进行交互的点对点电子现金系统, 即比特币[1].随着比特币等数字加密货币的关注度不断提升, 越来越多的学者开始对区块链技术进行研究.区块链技术拥有去中心化、数据安全、数据不可篡改等特点[2], 使得其在数字货币、数据存储、数据鉴定和金融交易等领域都有很好的应用前景[3].但目前区块链系统存在着资源消耗过大以及交易时延较低等问题[4], 限制了区块链技术的发展.
共识算法是区块链最为核心的技术, 影响着区块链系统的性能, 目前共识算法按照区块链的类型可以分为公有链共识、私有链共识和联盟链共识三类[4].工作量证明[5](Proof of Work, PoW)是应用于公有链的共识算法, 但其依靠计算机计算能力来完成共识的机制带来了资源浪费的问题, 文献[6]提出了股份授权证明(Delegated Proof of Stake, DPoS)算法来解决这一问题, 但该算法依赖数字货币才能完成共识操作, 而实际的区块链技术的应用场景不存在数字货币, 导致此算法的实用型较差; 不同于公有链, 私有链主要应用于企业的内部, 网络中不存在拜占庭节点, 拜占庭节点是指故意发送错误信息而导致整个网络不能达成共识的节点, 因此私有链中大多采用传统的分布式一致性算法Raft[7]来完成共识操作; 联盟链介于公有链和私有链之间, 其网络由经过授权的联盟成员共同维护, 联盟链中主要使用PBFT[8]算法, 但此算法为解决拜占庭将军问题, 需要通过时间复杂度为$O(N^2)$的网络通信才能完成共识(N为网络中节点的总数), 给网络带宽带来了巨大的压力.针对这一问题, 文献[9]提出将DPoS和PBFT算法相结合, 根据节点的股份投票选出部分节点来参与共识, 减少了共识过程中节点间的通信量, 但此算法与DPoS算法有相同问题, 即需要数字货币才能完成共识操作; 文献[10]和[11]则提出在网络中不存在拜占庭节点的情况下, 简化PBFT算法的一致性协议, 使共识过程的时间复杂度从$O(N^2)$降到了O(N), 但在存在拜占庭节点的情况下, 会执行和PBFT算法类似的过程, 算法的性能也退化到和PBFT一样的地步.
目前联盟链更加适用于各种应用场景的需要, 因此本文作者针对联盟链使用的PBFT算法存在的问题, 基于PBFT算法的思想, 提出了一种新的算法SPBFT(Selection-based Practical Byzantine Fault Tolerance).SPBFT算法对PBFT算法的一致性协议进行了优化, 并引入积分机制和升降级机制, 使得算法在大部分时间内都执行优化的一致性协议.最后通过对比实验证明了在相同状况下, SPBFT算法的共识效率和吞吐量更高, 网络中的通信开销更低.
工作量证明算法(PoW)适合应用在区块链公有链系统中, 工作量证明过程可以分成求解和验证两个阶段, 求解阶段是进行大量复杂的数学计算, 求得一个数学解; 验证阶段则是进行简单的数学计算来验证求得的解是否正确, 在极短的时间内即可完成.这是一种完全不对称的计算过程, 其原因是算法设定求解成功的节点拥有记账的权利, 但网络中存在着大量节点, 系统希望每一笔交易都只有一个节点拥有记账权, 以免造成系统记账混乱, 因此增加求解的难度来实现此机制.PoW共识算法需要通过大量计算来保障区块链数据的一致性和正确性, 导致此算法需要消耗大量的计算资源和电力资源; 并且为保证数据的安全性, PoW算法的出块时间较长, 导致PoW共识效率较低.
DPoS共识算法的共识过程类似于“ 董事会决策” , 网络中拥有数字货币也就是拥有股份的节点可以进行投票来选择共识代表, 获得票数最高并且希望成为代表的前101个节点加入“ 董事会” .“ 董事会” 成员按照约定的记账时间轮流生成区块, 如果某代表在规定的时间片内没有生成区块, 则会被踢出“ 董事会” , “ 董事会” 的成员按照维护周期(一般为1 d)更新一次.DPoS共识算法较PoW共识效率更高, 也更加节约资源.但其依赖于数字货币才能完成共识的机制, 使得DPoS算法不适合应用于大部分区块链应用中.
PBFT共识算法是适用于联盟链中, 其设计的目的是解决拜占庭将军问题.拜占庭将军问题证明了在拜占庭节点数目为f, 网络中节点总数N大于3f情况下, 分布式系统能够达成共识, 其算法的时间复杂度为O(${N}^{(f+1)}$).PBFT共识算法网络中同样允许存在f个拜占庭节点, 也要求
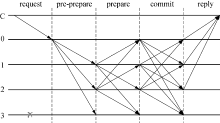
一致性协议是PBFT算法能够完成共识的核心协议, 主要分为预准备(pre-prepare)、准备(prepare)和提交(commit)3个阶段, 其执行过程见图1.
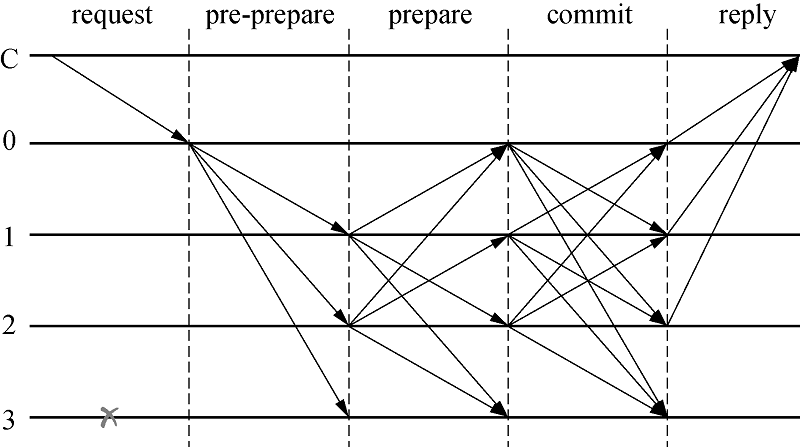 | 图1 PBFT算法一致性协议执行过程Fig.1 Execution process of the consistency protocol in PBFT algorithm |
1)预准备阶段:主节点会将接收到的客户端发送的请求生成预准备消息, 并将预准备消息广播给所有从节点, 消息格式为< PRE-PREPARE,
2)准备阶段:从节点收到主节点发送的预准备消息后, 会生成准备消息, 并将准备消息广播到其他节点, 同时将预准备消息和准备消息写进日志文件中.其消息格式为< PREPARE,
3)确认阶段:所有节点生成确认消息并广播到其他节点, 消息格式为< COMMIT,
通过图1可以看到, PBFT算法在执行一致性协议时节点间会进行大量的通信, 随着节点数量和交易数量的增多, 网络通信量会快速增长, 从而增加带宽的压力, 进而影响算法的共识效率.因此, 本文针对此问题, 并结合联盟链的特点, 在不存在拜占庭节点的情况下, 优化了一致性协议, 以降低节点间的通信量; 同时引入了积分机制和升降机机制, 使得算法能够在网络中出现拜占庭节点的情况下, 快速地恢复到最优状态, 使得算法在大部分时间内都能够执行优化的一致性协议.
在1.3节对PBFT算法中的一致性协议进行了分析, 在其准备阶段和确认阶段的验证过程中, 节点接收到超过
因此, SPBFT算法引入积分机制, 根据节点的积分将网络中的节点分成两类, 一类为共识节点, 其数量为
1)共识节点中不存在拜占庭节点, 拜占庭节点全部在候选节点中, 此时共识节点会执行优化一致性协议.
2)共识节点中存在拜占庭节点, 这时网络中所有的节点会执行PBFT算法的一致性协议, 保证算法的容错性.
SPBFT共识算法是为联盟链设计的, 在联盟链中, 大部分节点都是诚实节点, 因此, SPBFT算法在绝大多数时间内都会执行优化一致性协议.同时在算法中引入升降级机制, 当共识节点中出现了拜占庭节点, 在执行完一次PBFT算法的一致性协议后, 拜占庭节点会被剔除, 并从候选节点中根据积分选择一个节点加入共识节点, 保证共识节点大概率都为诚实节点, SPBFT算法将继续执行优化一致性协议完成接下来的共识操作.
PBFT共识算法的一致性协议在运行过程中需要完成两次复杂度为
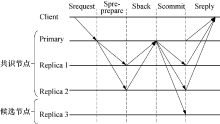
本文参考文献[12]中提出的一种简化一致性协议, 并结合本文的改进思路, 设计了如图2所示的优化一致性协议.
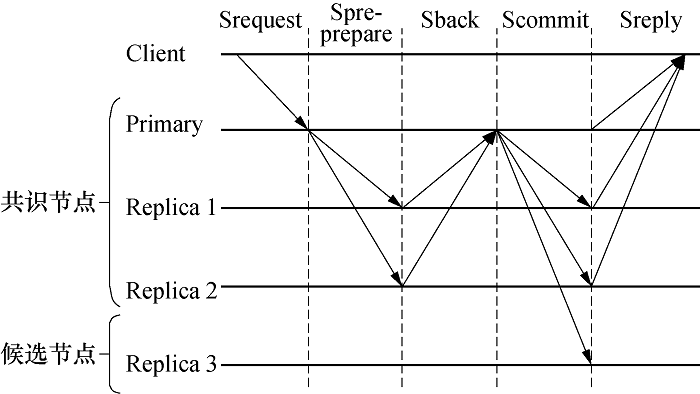 | 图2 优化一致性协议执行过程Fig.2 Execution process of the optimized consistency protocol |
协议的具体执行过程如下:
1)优化一致性协议发送请求阶段(Srequest):同PBFT算法的请求阶段一样, 客服端向主节点发送请求消息, 消息格式为< SREQUEST,
2)优化一致性协议预准备阶段(Spre-prepare):主节点接收客户端发送的请求后会生成预准备消息, 并将预准备消息广播到所有共识节点, 消息格式如下< < SPRE-PREPARE,
3)优化一致性协议反馈阶段(Sback):共识节点接收到主节点发送的预准备消息后, 首先会判断预准备消息中的g值和本地的g值是否相同, 如果不同, 则更新本地的积分信息s; 之后会生成反馈消息, 并将消息发送给主节点.消息格式为< SBACK,
4)优化一致性协议确认阶段(Scommit):主节点会接收到所有共识节点发送的反馈信息, 并且在所有反馈信息完全相同的情况下, 主节点会生成确认消息并广播到网络中的所有节点, 消息格式为< SCOMMIT,
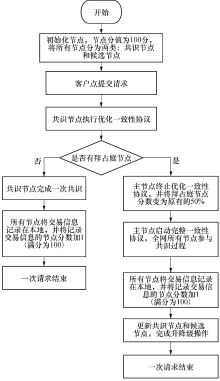
SPBFT算法是在PBFT算法上进行改进, 其也是通过网络中节点之间的互相通信来完成共识操作, 其通信过程根据一致性协议来执行.本算法对PBFT算法的一致性协议进行改进, 设计了一种优化一致性协议, 以减少共识过程中节点间的通信量.SPBFT算法的流程图如图3所示.
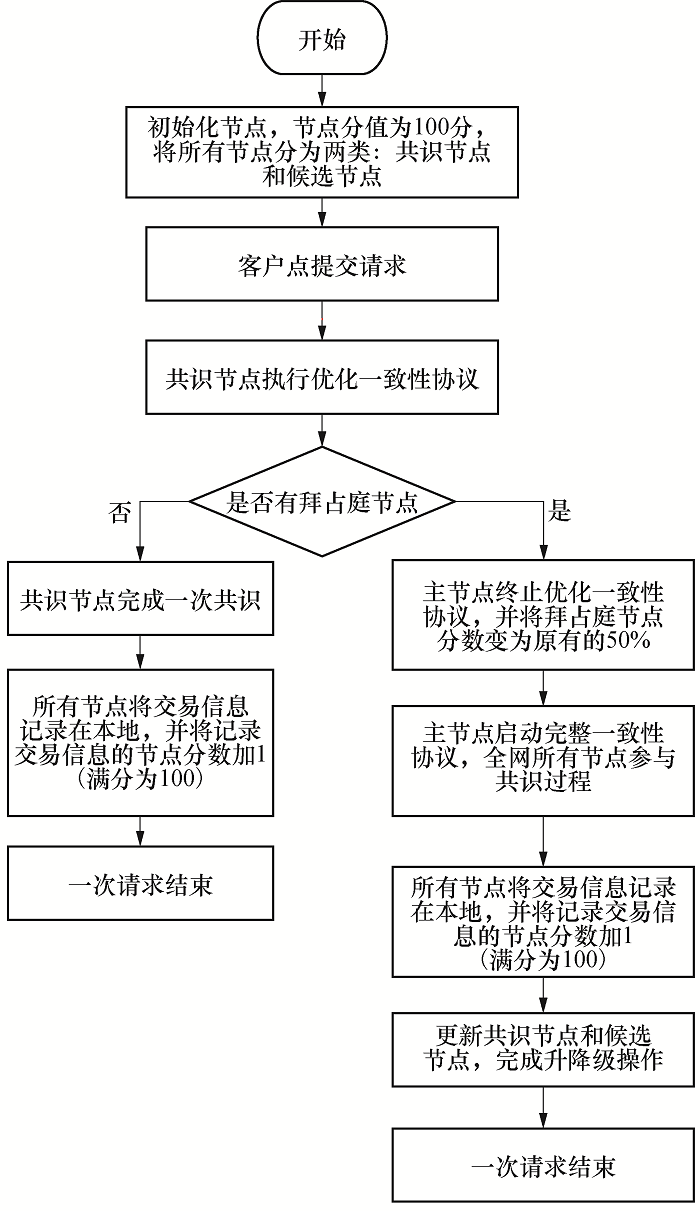 | 图3 SPBFT算法流程Fig.3 Flow chart of the SPBFT algorithm |
SPBFT算法的具体执行过程:
1)进行节点的初始化工作.首先, 用{0, 1, 2, …, |S|-1}共N个整数对网络中的节点进行编号, 将节点的积分初始化为100分, 设置f=(N-1)/3; 其次, 初始化共识节点集合CS和候选节点集合DS, CS={0, 1, 2, …, (N-f-1)}, DS={(N-f), …, (N-1)}, 共识节点的数量为:|CS|=(N-f), 候选节点的数量为:|DS|=f.
2)客户端向主节点发送一笔交易请求, 主节点接收请求后对请求消息进行编号, 之后主节点执行优化一致性协议.
3)所有共识节点执行优化一致性协议, 在优化一致性协议的确认阶段, 会对共识节点的状态进行判断.在此阶段, 主节点会接收所有共识节点的反馈消息, 并判断反馈消息< SBACK,
①若
②若
基于Java编程语言实现了一个小型的多节点区块链实验系统, 在该系统中对原PBFT算法和本文提出的SPBFT算法进行了验证.在存在拜占庭节点和不存在拜占庭节点两种情况下, 在交易时延、吞吐量和通信开销三个方面对两种算法进行比较分析.
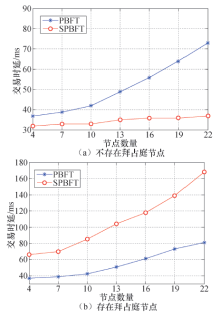
交易时延是指客户端向主节点发送一个交易请求到客户端确认完成共识的时间间隔.为不失一般性, 交易时延取200次交易的平均值, 并在不同节点个数的情况下对交易时延进行测试.图4所示为两种算法的交易时延对比.
图4(a)中, SPBFT算法在不存在拜占庭节点的情况下会执行优化一致性协议, 可以看出, 其交易时延明显优于PBFT算法.并且随着节点数目的增加, PBFT算法的交易时延增长较快, 而SPBFT算法的交易时延较为稳定, 增长缓慢.因此, 在节点较多的情况下, SPBFT算法的优势更为明显, 平均时延从55 ms下降到37 ms.与图4(a)相比, 图4(b)中PBFT算法的交易时延基本没有发生变化, 而SPBFT算法因要进行一致性协议的切换以及共识节点的更新等操作, 其交易时延明显增长.
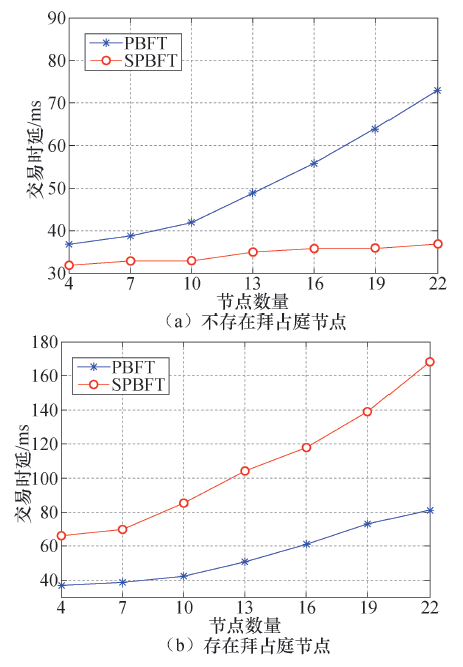 | 图4 两种算法的交易时延比较Fig.4 Comparisons on consensus completion time of the two algorithms |
通信开销指的是网络中节点在共识过程中产生的通信量.SPBFT算法设计的主要目的就是减少通信量, 降低通信开销, 减轻带宽的压力, 图5所示为两种算法的通信量对比.图5(a)中, 随着网络中在节点数目的不断增多, SPBFT算法由于采用优化一致性协议, 其通信量呈线性增长; 而PBFT算法需要通过复杂度为
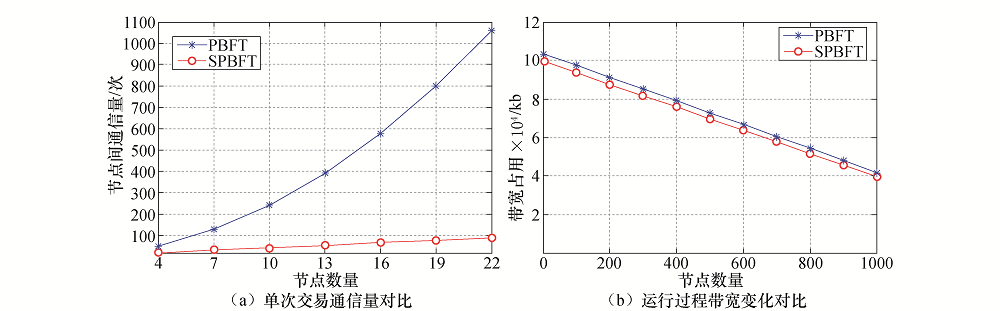 | 图5 两种算法通信量对比Fig.5 Comparisons on communication overhead of the two algorithms |
吞吐量指的是在单位时间内完成的交易的数量, 一般用TPS(Transaction Per Second)来表示.实验中设置客户端发送2 000条请求, 记录每秒能够完成共识的交易数量, 并在不同节点个数的情况下进行测试.图6所示为两种算法的吞吐量对比图.
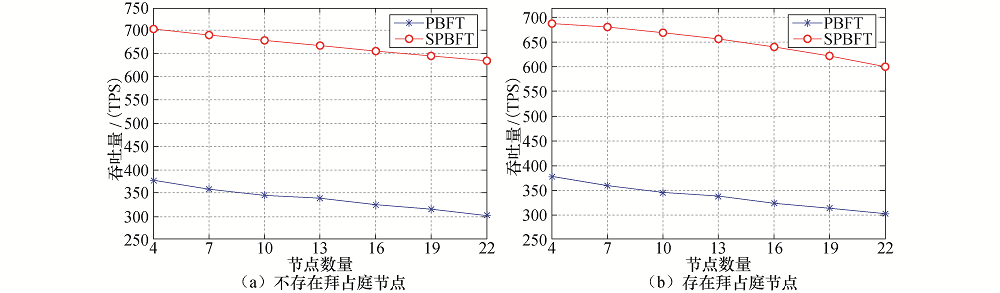 | 图6 两种算法的吞吐量比较Fig.6 Comparisons on system throughput of the two algorithms |
图6(a)中, 随着网络中节点数量的增多, 两种算法的吞吐量都呈现下降的趋势, 但从总体来看, SPBFT算法的吞吐量要远高于PBFT算法的吞吐量, 平均吞吐量从342 TPS提升到677 TPS.图6(b)中可以看出, 随着网络中节点数量的增多, 两种算法的吞吐量也都是呈现下降的趋势, 但SPBFT算法的下降趋势较大, 其主要原因是SPBFT算法在运行过程中, 在出现拜占庭节点的情况下, 算法会在一段时间内暂停共识过程, 完成一致性协议的转换, 执行PBFT算法的一致性协议, 在这段时间内算法只会完成一笔交易的共识工作, 影响了算法的吞吐量.但SPBFT算法吞吐量仍然大于PBFT算法的吞吐量.
1)基于PBFT算法的思想, 提出一种优化的共识算法.在不存在拜占庭节点的情况下, 优化了PBFT算法的一致性协议, 以降低节点在共识过程中的通信量; 同时引入积分机制和升降级机制, 动态的更新参与共识的节点, 使得算法能够快速恢复到最优状态, 保证算法在大部分时间内都执行优化的一致性协议
2)实验结果表明, 在相同的条件下与PBFT算法对比, 本文提出的SPBFT算法将共识过程的时间复杂度从
在未来的工作中, 可以对算法中积分机制和升降级机制进行改进, 增加节点的动态加入和退出网络的功能, 对算法完成进一步的优化, 增强算法的适应性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|