





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合运动目标检测和ResNet的车速车型智能识别
[梁栋a  , 何佳
, 何佳a , 石陆魁b , 王松a , 刘佳a ]
, 何佳, 王松|
|


第一作者:梁栋(1976—),男,河北南宫人,教授,博士,博士生导师,研究方向为桥梁结构智能检测.email:13622114075@139.com.
车速和车型作为重要的车辆信息,在道路监控系统中发挥着很大的作用.传统的基于视觉的车辆信息识别方式由于计算参数过大且提取的特征不足,难以满足智能交通实时性和普适性的需求.对此,提出了一种新的车辆信息识别方法,采用运动目标检测技术实现视频中车辆的提取,然后利用虚拟线圈法进行车速识别,再通过改进的残差网络对提取的车辆进行车型识别,有效地减少了计算参数,实现了对视频的快速处理,同时利用了残差网络极强的特征表达能力,提高了识别的准确率.此外,加入了重载车型的研究,有良好的应用前景.实验结果显示,系统车速识别平均绝对误差不超过6 km/h,车型识别平均准确率达到92.1%,针对小客车和小轿车的识别准确率高达98.7%,优于传统的识别方法.
As the important vehicle information, speed and type of vehicle play an important role in the road monitoring system. The traditional vision-based identification of vehicle is weak in real-time performance and universality, because the calculation parameters are too large and the abstraction of extracted feature is insufficient. In this regard, a new vehicle information recognition method is proposed. The vehicle extraction is realized by moving target detection, then the vehicle speed is identified by the virtual coil method, and the vehicle type is classified by the improved residual network. This method effectively reduces the calculation parameters, realizes the rapid processing of video, and utilizes the strong feature expression ability of the residual network to improve the accuracy of recognition. In addition, the classification of heavy vehicles has been added, which provides a good application prospects. Experimental results show that the average absolute error of speed identification is not more than 6 km/h, and the average precision of vehicle type identification is 92.1%, for minibuses and cars, the precision is as high as 98.7%, which is superior to the traditional identification method.
智能交通系统[1, 2](Intelligent Transportation System, ITS)不断发展, 在提高交通运输和管理效率的同时也对交通信息的获取提出了更高的要求.车速和车型是具有代表性的车辆信息参数, 其快速稳定的识别是智能交通研究的一个重要分支, 在车辆荷载研究、交通流量调查、违规车辆检测等方面发挥着重要的作用.在实际的交通监控视频中, 由于车辆外观复杂多样, 摄像机角度和分辨率的变化以及交通场景的环境影响, 一直很难实现对车辆信息的稳定快速识别, 大部分视频数据只能用于事后检索, 不能实时的应用于交通管理.
传统的车辆信息检测主要采用地感线圈检测、雷达检测、激光检测三种方法.这三种方法均达到了执法的标准, 在车速及车型的检测中发展的较为成熟, 是目前交通系统应用的主流方法.但是传统检测方法所需的设备十分昂贵, 且由于设备布置在路面下, 后期维护需要对路面结构进行开挖, 在影响交通的同时也会破坏路面结构的稳定.
基于视觉的车辆信息检测方法可以利用当前存在的大量监控设备对车辆进行无损识别, 克服了传统方法检测成本高且后期养护维修困难的问题.目前, 基于视频的车速识别在原理上主要分为运动目标检测和运动目标跟踪两种, 比较常用的方法有:1)虚拟线圈法, 通过在视频中布置虚拟线圈来模拟路面下铺设感应线圈进行车速检测, 操作简单, 运算量小, 在满足实时处理的同时还拥有较高的测速精度.2)车牌定位法, 通过对视频中车辆的车牌进行定位和跟踪来进行车速的检测, 在识别车速的同时还能提取车牌信息, 但是该方法对摄像机安装位置要求较高, 同时需要视频有足够高的分辨率来获得车牌信息.3)特征匹配法, 通过对视频中车辆进行特征提取再进行特征匹配进行车速检测, 该方法精度较高但是由于参数较大不能满足实时性的要求.4)运动矢量法, 对视频中的车辆进行实时跟踪获得移动矢量的大小和方向, 再进行换算得到车辆速度.该方法鲁棒性较好, 但是计算量过大不易满足实时检测的要求.基于视觉的车型识别主要采用匹配的方法:1)特征匹配, 人工设计提取相应车辆特征进行车型识别.文献[3, 4, 5]通过提取车辆的外观特征(SIFT、HOG)进行车型识别.文献[6]利用车辆图像的Haar特征并结合adaboost进行车型识别.这些人工设计特征由于表现力不足, 不能表达图像的高阶信息, 鲁棒性较差.2)模型匹配, 对车辆图像进行整体建模然后利用相似性准则判断车辆类型.文献[7, 8]利用多角度车辆的长、宽、高信息与已有模板比较进行车型识别, 但是该方法不能有效捕捉车辆边缘信息极容易漏检.
近年来, 深度学习不断发展, 卷积神经网络在目标识别和图像分类领域表现十分突出, 并取得了重大突破.与人工设计的特征提取方式相比, 卷积神经网络以原始图像作为输入数据, 用大规模数据集作为驱动, 自动提取目标图像的识别特征, 克服了人工设计的特征提取方式由于关注点片面、抽象性不足, 在复杂的环境下适应性较差、表现不佳的问题.此外, 卷积神经网络还能抵抗图像的形变干扰, 例如平移、旋转、缩放等, 极大地提高了目标识别的准确率.在网络结构上, 卷积神经网络主要由输入层、卷积层、池化层和全连接层组成, 网络的层数越多, 提取到的不同层次的特征就越丰富, 同时, 随着网络深度的加深, 提取的特征越抽象, 越具有语义信息.但是, 传统的卷积网络或者全连接网络在信息的传递过程中会存在信息丢失和损耗, 简单的增加深度不仅会造成计算量增加, 还会产生退化问题从而增加网络训练的难度.基于卷积神经网络, 国内外学者展开了广泛的研究:文献[9]利用卷积神经网络(Convolutional Neural Network, CNN)并结合SVM分类器进行粗粒度车型识别, 对小车、客车、货车进行分类.文献[10]采用基于AlexNet结构的DCNN网络模型对车型进行分类.文献[11]提出一种多分支多维度特征融合的车型识别Fg-CarNet模型, 在CompCars数据集上有较高的识别准确率, 但模型只针对车辆正脸图像, 所以对摄像机角度有严格的限制.这些研究虽然发挥了卷积神经网络的优势, 在车型识别中取得了较高的准确率, 但是由于网络深度的局限性, 提取的特征抽象性不足, 只能依赖单一角度的车头图像, 不能满足真实情况的多角度车型识别.
随着残差网络(Residual network, ResNet)的问世, 深度学习迎来新一轮的变革[12, 13, 14, 15].相比之前的卷积神经网络, 残差网络提出的残差单元解决了由于网络深度的增加带来的退化问题, 使网络深度有了质的飞跃, 拥有极强的特征表达能力和惊人的速度, 为高级语义特征的提取和分类创造了条件.
在这种背景下, 本文作者建立了一套结合运动目标检测和ResNet的车速、车型智能识别方法, 充分发挥了运动目标检测技术参数少、实时性高的特点, 实现对视频图像的快速处理, 满足了实时性的需求.在车速识别中, 车辆经检测后通过虚拟线圈进行车速计算, 由于只需要对线圈内部图像进行处理, 检测效率较高.在车型识别中, 将运动目标检测后提取的车辆图片输入车型识别网络进行二阶段识别, 极大地提高了车型识别的准确率.此外, 为了挖掘网络深度的优势, 提取更有代表性的高阶特征来满足真实条件下复杂的识别要求, 将车型识别网络进行改进, 采用先进的ResNet残差模块, 建立了26层残差网络, 并添加类别中心正则化约束来提高相似车型的识别精度, 考虑到之前的研究中忽略了对路面破坏影响最大的重载车, 应用前景受限, 本文在车型分类中加入了大型货车和拖挂车, 为后续车辆荷载研究提供了技术支持.
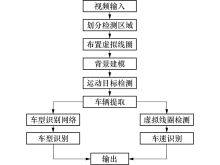
结合运动目标检测和ResNet的车速、车型智能识别方法, 整体架构如图1所示.
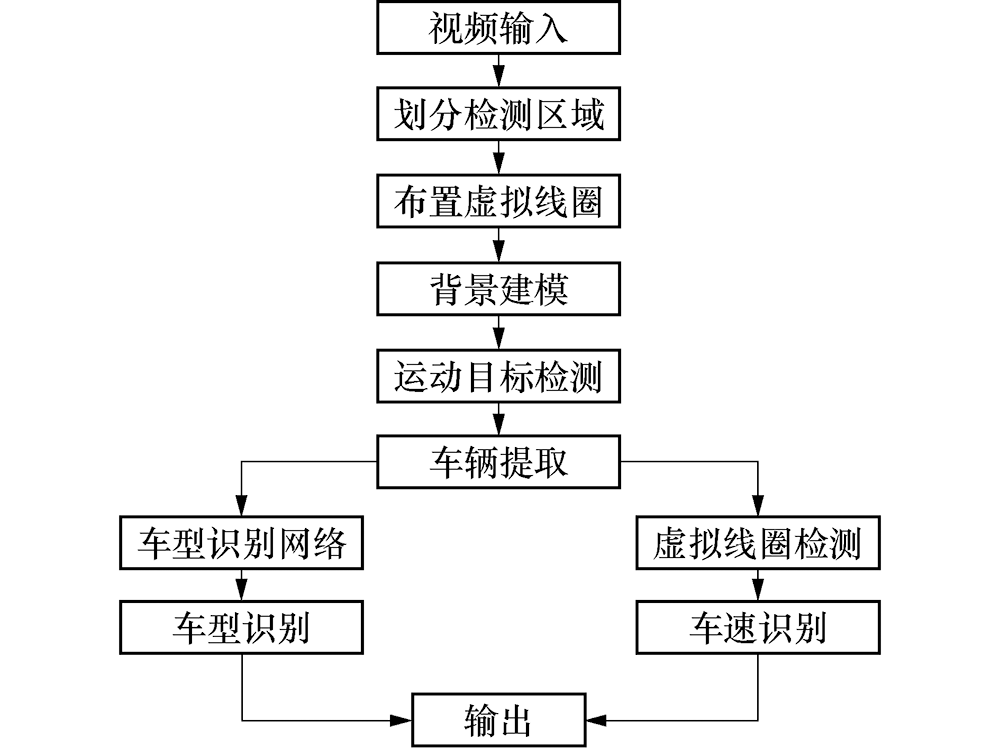 | 图1 本文方法的总体架构Fig.1 Overall architecture of the proposed method |
在真实的监控视频中, 车辆移动较快, 视频帧率较大, 所以对检测的实时性提出了更高的要求.此外, 考虑到检测所需的摄像机处于固定位置, 不会使视频中的场景发生全局移动, 所以本文选用背景差分法对视频中的车辆进行检测.背景差分法是一种常用的运动目标检测方法, 其原理是将当前帧的图像和背景模型进行差分来检测运动区域, 检测的性能主要取决于背景建模技术.在实际应用中, 由于视频场景本身的复杂性和外界环境干扰的存在, 如车辆进出对原场景的影响、摄像机的抖动、光照变化等, 使得静止背景不能满足实际需要, 需要根据视频的帧间信息来更新背景.
1.1.1 背景建模
采用均值法进行背景建模, 基本思想是在视频中连续选取N帧图像, 计算N帧图像像素灰度值的平均值来代替背景区域的灰度值.这种建模方式因为算法简单所以计算速度较快, 能够满足实时检测的需求, 此外, 这种方法还可以消除背景噪声对车辆检测的影响.具体计算式如下
式中:
式(2)说明, 新的背景模型可以由上次计算得到的背景模型
1.1.2 阈值的选取
在视频中提取目标车辆需要对视频图像进行分割, 而图像分割的关键在于阈值的选取, 这表现在:如果阈值取的过大, 那么就存在将运动车辆的像素点误判为背景像素点的可能性.同理, 如果阈值取的过小, 也可能产生将背景像素点判断为运动车辆像素点的错误.为了使系统具有良好的自适应性, 本文不采用固定阈值的方法, 而采用阈值分割的方法自动确定阈值的大小.阈值分割主要有直方图双峰法、基于模糊聚类方法、基于遗传算法的Ostu算法等, 其中直方图双峰法适用于目标和背景的对比度较大的情况, 模糊聚类法计算量过大不能满足系统的实时性要求, 故本文采用Ostu算法.Ostu算法是由图像的灰度直方图, 根据类间距离极大准则确定分割门限值, 算法简单且分割准确, 描述如下:
设图像有
图像总的灰度均值为
由此可以得到
$σ ^2$ (t)越大, B、F区间灰度差别越大, 所以最佳阈值就是使得类间方差$σ ^2$ 达到最大时t的取值.
1.1.3 运动目标的提取
识别目标需要对图像数据进行前景提取, 步骤分为:
1)将视频图像的当前帧与背景帧相减, 进行前景提取.
2)找出前景目标, 并对图像进行二值化处理, 如图2所示.
 | 图2 二值化处理结果Fig.2 Binarization results |
3)采用数学形态学方法对二值化后的图像进行处理, 本文采取的步骤是先腐蚀后膨胀.腐蚀的目的是去除二值化图像中的椒盐噪声, 为车辆目标的提取创造有利的条件.膨胀是为了消除车窗的影响, 因为大型车辆通过时, 由于侧面车窗面积较大, 会将二值化的图像断裂为两个目标, 从而产生误检, 经过膨胀处理后, 可以得到更为完整的车辆轮廓形状.
4)连通目标寻找.图像经二值化处理后,
基于视频的车速检测, 主要有两种测定方式:1)通过车辆运动固定位移所需的时间进行测定.2)通过车辆运动固定时间所产生的位移来进行测定.其中, 车辆运动的时间可以由图像帧差得到, 但由于摄像机的透视作用, 即视频图像坐标与实际三维道路坐标存在映射关系, 使得车辆运行的实际位移很难从图像中得到.基于这点, 本文选用虚拟线圈法进行视频中车辆的车速识别, 通过对实际车道进行标定得到线圈间的实际距离, 然后由帧差得到车辆通过相邻虚拟线圈的时间差, 最后根据速度公式计算出车速.
1.2.1 虚拟线圈的设置
根据实际道路已知标定点设置虚拟线圈, 线框横向垂直于道路方向, 纵向平行于道路方向.虚拟线圈的大小和个数应根据实际情况做出自适应调整, 位置一般选在视频的近端, 目的是减少摄像机透视作用的影响.为了防止多车辆引起的误检, 相邻虚拟线圈的距离不宜过大.
1.2.2 虚拟线圈状态判定
虚拟线圈的状态主要是通过像素灰度变化来判定, 具体步骤分为:1)计算当前的帧线圈区域内前景图像灰度值$F_I$ (x, y)和背景图像灰度值$B_I$ (x, y).2)将前景图像灰度和背景图像灰度进行差分得到$D_I$ (x, y).3)若灰度变化大于阈值则认为有车辆经过, 若灰度变化小于阈值则认为没有车辆经过或者已经离开线圈.4)计算相邻线圈激活的时间差.虚拟线圈的布置和处理过程如图3所示.
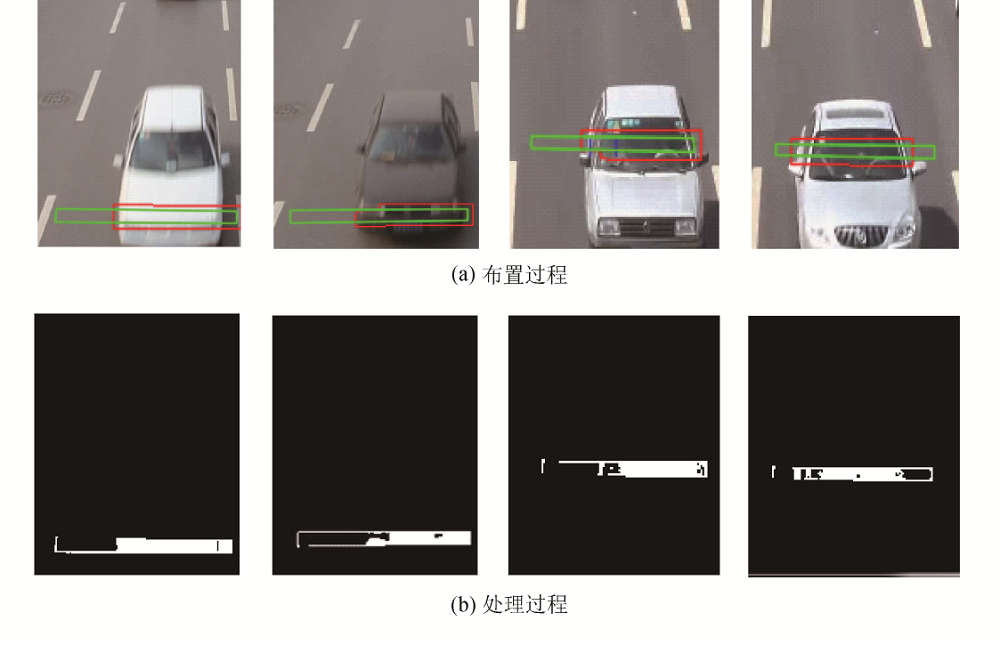 | 图3 虚拟线圈的布置和处理过程Fig.3 Virtual coil arrangement and processing |
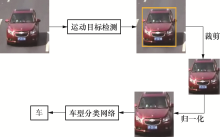
基于视频的车型识别主要包括两部分:1)目标检测, 即在视频序列帧中找到检测的目标.2)车型分类, 对检测到的目标按一定标准进行车型的分类.本文的车型识别模块以运动目标检测后的结果作为输入, 车型分类网络采用改进的残差网络, 车型识别的流程如图4所示.
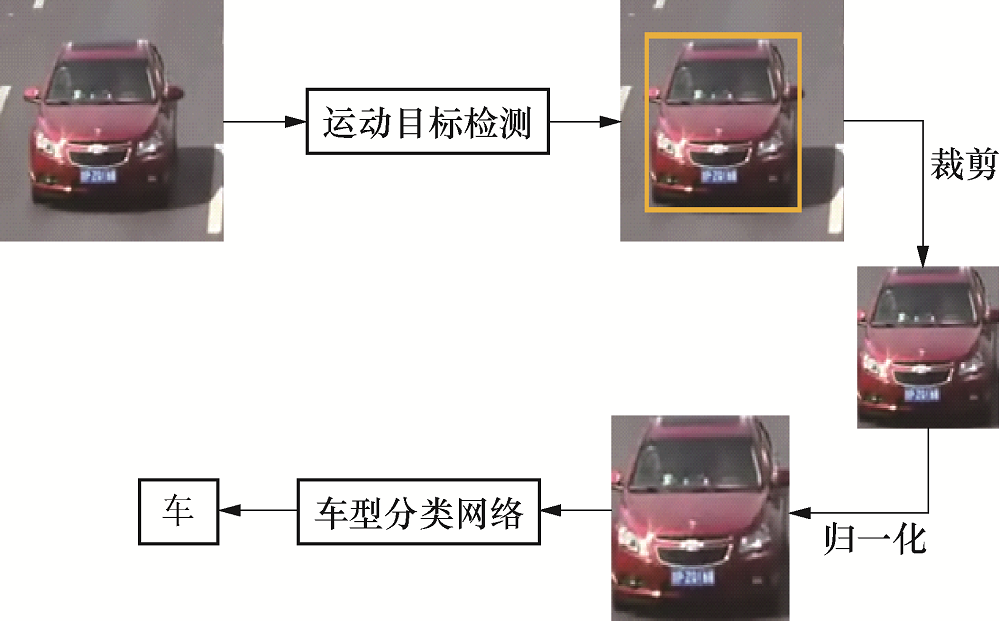 | 图4 车型识别流程Fig.4 Flow chart of vehicle type identification |
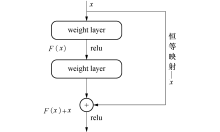
传统的卷积神经网络可以通过增加网络层级使模型精度得到提升, 但网络层级达到一定数量之后, 训练集和测试集的精度反而会下降, 这种退化的问题使得深度卷积神经网络难以训练.同时, 卷积神经网络在反向传播的过程中需要不断传播梯度来调整权重, 随着网络层级的增加, 梯度会逐渐衰减直至消失, 导致参数矩阵无法进行有效的调整.残差网络提出了新的单元结构— 深度残差单元, 如图5所示, 这种结构很好的解决了神经网络在训练过程中产生的梯度消失和退化的问题, 使深层神经网络的训练成为可能.残差网络的主要思想是在网络中增加直连通道, 不再学习一个完整的输出, 而是学习上一个网络输出的残差, 极大的简化了学习的目标和难度.具体方式是将隐含层设置为
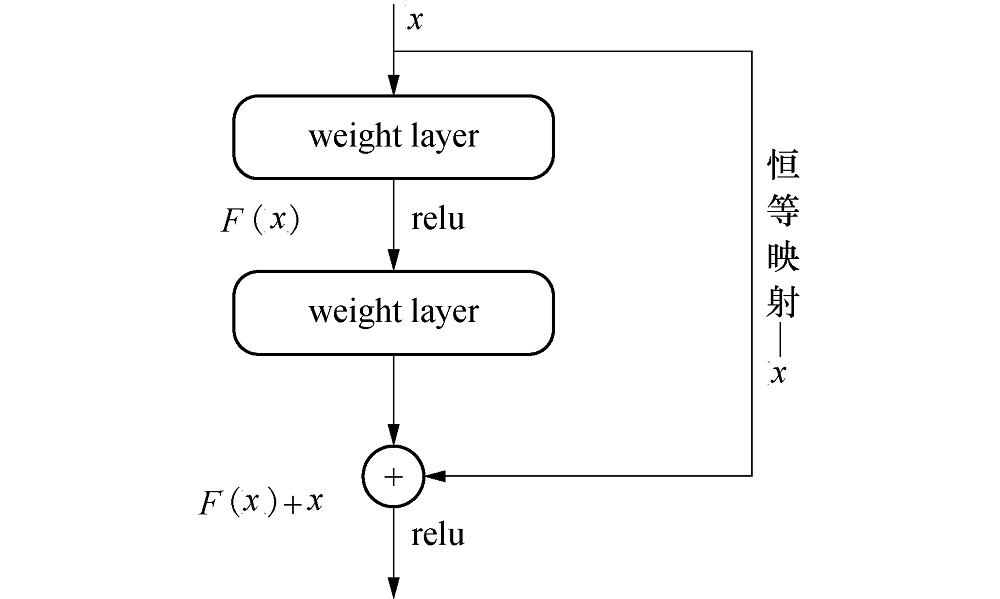 | 图5 ResNet的残差学习模块Fig.5 Residual learning module of ResNet |
残差单元内部连接BN(Batch Norm)层和Scale层对数据进行规范处理, 实现权值参数的归一化, 输出由多个卷积层级联的输出和输入元素间相加, 再通过ReLU激活, 然后级联起来, 构成残差网络.这种网络结构采用捷径连接(shortcut connection), 不会增加新的参数, 同时使用了较少的池化层, 即使加深网络层数也能保持较快的计算速度; 每一层的特征呈现递进关系, 具有显著的层级; 解决了梯度弥散问题, 有效的增加了网络的特征提取能力.
本文在传统ResNet的基础上, 结合车辆图片的特点, 尝试改进残差结构, 减少网络层数, 提高计算速度和车型识别精度, 提出了一种改进的深度残差网络结构, 具体参数如表1所示.
| 表1 本文提出的ResNet-26具体网络参数 Tab.1 Specific network parameters of ResNet-26 |
网络输入为192× 192× 3的RGB图像, 第一层采用原始ResNet的策略, 使用7× 7的卷积核, 通道数为64, 步长为2.然后连接3× 3的最大池化层, 步长为2, 这里采用重叠池化增强目标形变的鲁棒性.最大池化层之后连接8个残差单元, 最后与平均池化层相连, 输出为1× 1× 2048, 最后作用于5个神经元的全连接层, 网络的总层数为26层.
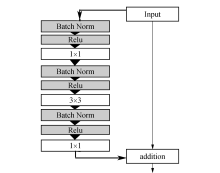
本文使用的残差单元如图6所示, 三个卷积层分别为1× 1, 3× 3, 1× 1, 其中1× 1的卷积层作用是改变维度, 3× 3的卷积层继承了VGG网络的性能, 单元采用预激活方式, 所有的卷积层都使用ReLU作为激活函数, 即在使用激活函数和卷积操作之前先进行批正则化, 这种结构大大减少了模型的参数并加速了训练速度.
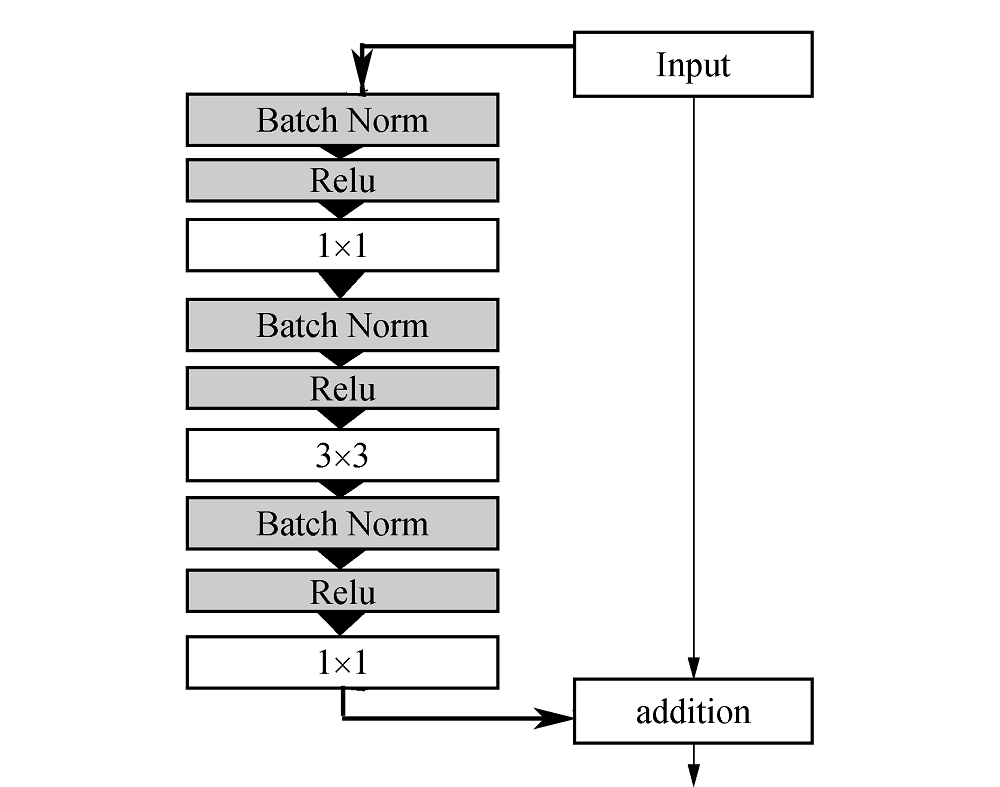 | 图6 本文所用的残差结构单元Fig. 6 Residual unit used in this paper |
卷积神经网络的特征提取能力一般通过Softmax loss函数进行评价, 通过反馈的损失值来优化网络参数.在网络训练过程中, 随着迭代次数增加, 损失值逐渐降低, 样本的种类慢慢被分开.
Softmax loss函数定义如下:
式中: $x_i$ 代表第i个深度特征; b为偏置项; $W_j$ 为最后一个全连接层中权重的第j列; m、n为样本数量和类别数.
实际的车型识别过程中, 由于数据分布十分复杂, 同类数据在数据空间的距离比不同类在数据空间的距离还要大的情况普遍存在, 这使得Softmax loss函数不能很好的引导网络进行分类学习.例如, 大型货车和大型客车由于在多角度存在相似性, 很容易发生误判.所以, 为了训练出来的特征不仅可分, 而且差异必须要大.
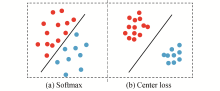
针对这种情况, 本文采用类别中心正则化约束[18], 中心思想是通过添加Center loss让Softmax训练出更有内聚性的特征.具体方式是通过控制每类样本和该类样本中心的偏移, 让同类的样本聚合在一起, 使学习到的特征具有更好的泛化性和辨别能力, 如图7所示.
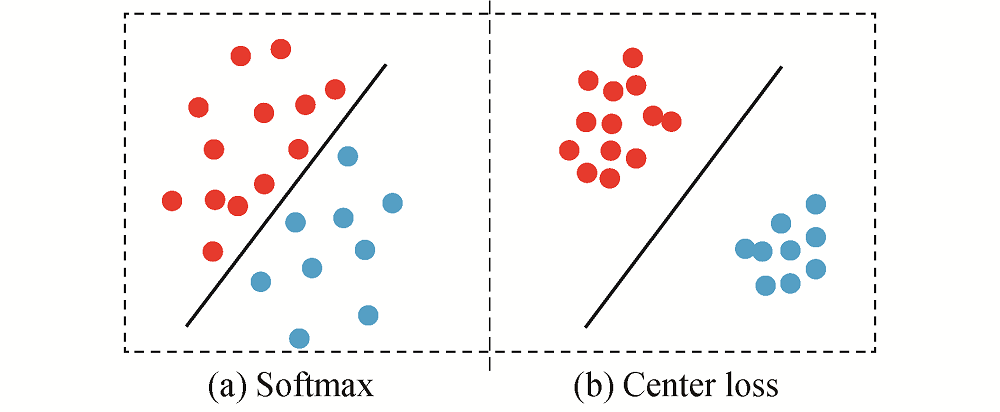 | 图7 Softmax和Center loss处理结果对比Fig. 7 Comparisons of Softmax and Center loss processing results |
Center loss函数定义如下:
式中:
在实际训练中, 损失值
本文的数据来源于真实情况下的道路监控视频, 对6个不同的场景进行图像提取应用于车型识别训练.根据车辆荷载的特性, 本实验主要以车重为指标, 将车辆分为五类, 分别是小轿车、小客车、大客车、大型货车、大型拖挂车, 各类车型如图8所示.
 | 图8 各类车型数据集样例Fig.8 Sample data sets for various vehicle types |
车型识别训练集包含图像30 000张, 测试集从每类车型图像中随机产生, 共5 000张, 训练集用于训练模型, 测试集用于测试模型的泛化能力.由于网络参数复杂而训练集图片数量有限, 本文采用数据增强的方法增大训练集的数量, 包括随机剪裁、水平翻转、光学畸变等.其中随机剪裁在原始图像中切出一系列子区域作为训练样本, 水平翻转在不改变标签的基础上对数据集扩充至原来的2倍, 光学畸变即改变图像的颜色、饱和度、对比度等.
对道路监控某车道视频流进行实验, 视频文件长10分20秒, 帧率为25帧/秒.对车速进行测量时采用室外报速的方式获取真实的速度值, 车型识别中小轿车、小客车、大型客车、大型货车、拖挂车分别记为0, 1, 2, 3, 4, 截取部分实验结果如表2所示, 其中:测试时间为2分16秒, 人工计数车辆为26, 有效测试车辆为24(指车身完全经过检测区域)。预测效果实例如图9所示.
| 表2 实验部分结果 Tab.2 Partial results and description of the experiment |
 | 图9 预测效果图Fig.9 Effect diagram of prediction |
3.3.1 目标检测分析
本文通过运动目标检测技术实现视频中车辆的识别, 计算量小, 处理速度快, 满足了实时性的要求.当视频中光线较暗时, 可以将二值函数的阈值调高来降低光照对背景差分的影响, 由于阈值的提高而产生的图像损耗可以通过形态学处理进行弥补, 本文采取提高膨胀函数内核的形态学处理方法来获得更为完整的车辆轮廓.在夜晚条件下, 由于车辆探照灯的影响, 目标检测会出现误检和错检, 后续的研究可以有针对性地消除车灯的影响.
3.3.2 车速准确率分析
视频图像处理的是车辆进入和离开虚拟线圈的图像, 当车辆变道行驶时, 会导致测量目标不明从而出现误判, 同时背景噪声处理不完整时, 也会影响测速的精度.实验结果表明, 本文的算法能够以25 帧/s 的速度实时地处理视频图像并检测出车辆瞬时速度, 可检测的车速范围为0<
3.3.3 车型识别算法分析
图10显示的是本文网络提取到的车辆特征图可视化结果, 其中图10(d), (e)分别为conv1层, conv3层所有特征图按1:1融合后的整体特征图.为了使图像具有可比性, 选取每层得到的前16个特征图进行比较.可以发现, 浅层网络提取的主要是纹理、细节特征, 其对应的特征图分辨率较高, 包含了更多的特征; 深层的网络提取到了更高阶的特征, 例如轮廓、车灯、车牌等, 其对应的特征图分辨率较低, 提取的特征更具有代表性.
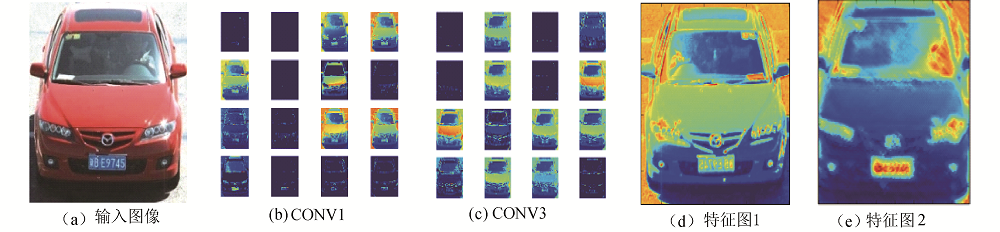 | 图10 车辆特征可视化结果Fig.10 Visualization results of vehicle features |
为了突出本文方法的优势, 在车速检测中, 将本文的实验监控视频分别采用Harris角点检测法[16]和基于卡尔曼滤波跟踪的运动矢量法[17]进行相同实验环境的车速检测, 实验平台的环境为WIN10+visual studio2015, Intel i7六核3.20 GHz处理器, Nvidia显卡, 16 G内存, 并使用了基于C++的Caffe框架包.车速检测的帧差间隔为25帧, 车辆目标在视频中平均运动时间为13 s, 测试三种不同检测方法的平均绝对误差和进行一次车速检测的运行时间, 结果如表3所示.由对比可知, 本文采用的虚拟线圈法可以有效的对视频车辆进行车速检测, 平均绝对误差不超过6 km/h, 不仅保持了较高的识别精度还满足了实时性的要求, 相比其他方法更具有实用价值.
| 表3 不同车速检测方法的比较 Tab.3 Comparisons of different speed detection methods |
在车型识别中, 为了测试本文所用网络模型的性能, 将其与深度卷积神经网络模型中表现较好的VGG16、AlexNet模型进行对比实验, 使用相同的测试集, 测试不同模型对5类车型的准确率和召回率, 结果如图11所示.
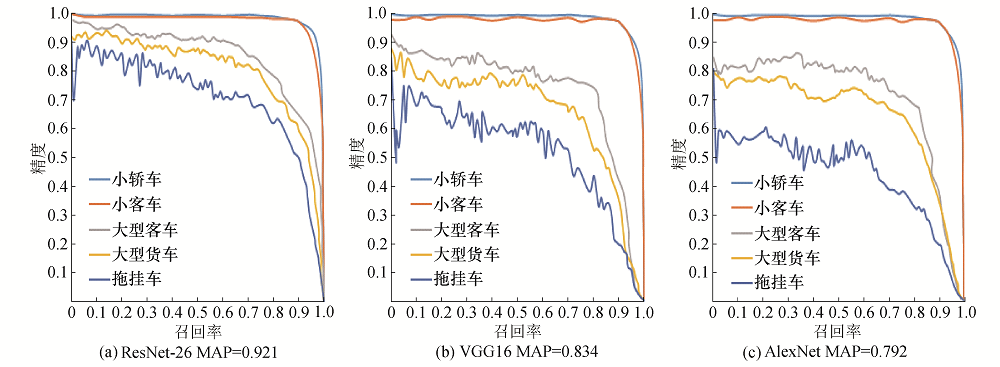 | 图11 模型性能对比Fig.11 Performance comparisons of different models |
由对比可知, 本文的模型表现性能最佳, 针对每类车型的识别都保持了最高的准确率, 尤其对于小客车和小轿车的识别, 准确率高达98.7%, 五类车型的平均准确率达到了92.1%, 远远优于VGG16和AlexNet模型.
1)建立了一套实时的车速及车型智能识别系统, 在车速识别中应用计算参数较少的运动目标检测技术, 占用较低的计算资源, 满足了系统实时性的需要.
2)在车型识别中, 选用先进的ResNet残差模块建立了26层深度残差网络, 通过增加网络深度提取到高阶特征, 增强了系统在现实复杂环境下的鲁棒性, 利用残差学习的优势减少了网络参数并加快了收敛速度, 同时结合类别中心正则化的度量学习方法, 有效的引导网络学习更有区分度的特征, 提高了相似车型识别的准确率.实验说明, 本系统识别准确率高、速度快, 能够满足复杂的现实交通场景视频监控的需要.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|