

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于浮动车大数据与网格模型的城市交通拥堵识别和评价研究
[闫学东 , 刘晓冰, 刘炀, 马世霞]
, 刘晓冰, 刘炀, 马世霞]
, 刘晓冰, 刘炀, 马世霞]
|
|



第一作者:闫学东(1975—),河北沧州人,男,教授,博士,博士生导师. 研究方向为交通运输规划与管理.email:xdyan@bjtu.edu.cn.
闫学东,交通部综合交通大数据应用行业重点实验室首席科学家,入选中组部第一批青年千人计划、万人计划和教育部新世纪优秀人才计划.近年来主持国家自然科学基金委重大国际合作研究项目,自然科学基金委重点项目,国家自然科学基金委会面上项目,国家“863”、“973”计划项目,世界银行与交通部联合项目等多项国家和省部级重要课题.发表SCI/SSCI 期刊检索论文120 余篇.兼任《JournalofTransportationSafety&Security》国际期刊主编,英国工程技术学会会士(IETFellow),中国智能交通协会安全领域专家,以及《AdvancesinTransportationStudies》《中国安全科学学报》《交通信息与安全》等国内外学术期刊编委会成员.
随着机动车辆的迅猛增长,城市路网呈现出事件多发、通行状态多变的特征,大城市的交通问题日趋严重.借助大数据技术,通过对城市路网中海量浮动车轨迹数据的深入挖掘,能够实现对复杂交通状态的快速识别和准确分析.本文首先对北京市浮动车的海量数据进行校准和清洗.其次,针对不同的研究内容,构建不同尺度的网格模型.然后,根据网格内节点对行程时间的历史数据,识别常发拥堵区域;结合实时行程时间数据,识别偶发拥堵事件.最后,通过对网格交通运行指数进行密度聚类,从空间范围上将大城市拥堵区域的类型划分为“点-线-面”3个层级对交通拥堵进行评价研究.本研究不以道路矢量地图为基础,仅通过浮动车轨迹数据,便可以实现对交通拥堵的高效识别和宏观拥堵的评价.
As the rapid growth of automobiles, the road networks of the megacities present the characteristics such as the frequent occurrence of traffic incidents and various traffic states, which makes the traffic problems more and more severe. With the big data technologies, we can deeply mine the trajectory data of floating vehicles in road networks and then realize the efficient identification and accurate evaluation of the complex traffic operation states. In this paper, we firstly validate and clean the humongous Beijing floating vehicles trajectory data. Secondly, according to the specific objectives of research, the grid models with different scales are developed. Then,the reoccurring traffic congestion regions are identified based on the historical data of vehicle travel time between the paired nodes within grid cells, and the nonrecurring congestion regions are discerned using the real-time travel time data. Finally, the method of Density-Based Spatial Clustering of Applications with Noise(DBSCAN) is applied to cluster the congested cells based on the traffic operation index. The traffic congestion statuses are evaluated in terms of point, line typeand region types.This research is not based on vector maps but takes advantages of the trajectory data of floating vehicles to realize a high efficient identification and macroscopic evaluation of traffic congestion.
随着我国城市化比例的逐步提高、城市扩张速度的加快及城市机动车保有量的快速增长, 国内一线城市如北京、上海、广州和深圳等地的交通拥堵问题越来越突出, 交通拥堵已经给城市可持续发展带来了巨大的压力和挑战.按照道路交通拥堵形成的原因, 交通拥堵被分为常发性及偶发性两种类型[1], 其识别与时空特征分析是道路交通管理领域的热点.大城市交通拥堵识别具有大需求、跨时空、多点段的特性, 而大数据的技术手段能够较好地应对这些特性[2, 3].其中, 以出租车为载体的浮动车时空数据能够匹配基础道路GIS数据, 采集范围和精度能够给道路拥堵的监测提供较好的数据基础[4], 同时, 连续的出租车轨迹可以反映出经过路径及行驶速度[5, 6], 对于交通运行表现评估, 特别是交通拥堵的确认, 体现出极其重要的价值.
针对常发拥堵识别, 大量研究将浮动车轨迹数据与线圈、视频监控等数据相结合, 提取路网中的常发拥堵区域及时段[7], 但单纯应用浮动车轨迹数据对大规模路网进行常发拥堵区域和发生时间识别的研究尚有进一步开展的空间[8].针对偶发拥堵, 已有研究将统计方法应用到浮动车轨迹数据分析中, 在对路段上浮动车轨迹数据长期积累后, 分析浮动车的路段通行速度的时序变化识别偶发拥堵[9].非常规的交通情况也可以通过路段的行程速度反映出来, 在瓶颈或者拥堵路段, 浮动车的平均速度通常低于10 km/h, 因此使用路网上各路段识别出的速度和时间特性, 可以找到每条道路上独特的交通模式特征, 从而描述区域交通状态[10].目前已经有基于密度的聚类、支持向量机模型、神经网络模型等算法用于非常发性拥堵监测[11].
已有研究主要存在两点问题, 第一, 轨迹与路段的匹配计算量较大, 难以对海量数据进行实时计算; 第二, 目前的研究方法大多依赖于高精度的城市矢量地图, 研究适用性较差.另一方面, 浮动车数据分析给出了大量的关于城市路网交通运行模式的研究成果[12], 然而, 很少有研究使用浮动车数据进行常发性拥堵的评价.实际上, 传统的出租车浮动车数据特别适合评估城市的交通拥堵水平以及调查城市道路网的拥堵时空模式[13], 因为浮动车数据是短时间内的大规模样本, 能够提供全面而且更好的交通网络运行状况.本文作者主要从理论研究层面探索海量轨迹数据应用于交通运行计算的方法, 其中核心在于通过构建地图网格化模型, 提供一套通过浮动车轨迹数据, 不依附于道路矢量地图的交通运行参数计算方法.
近年来GPS技术的推广使得基于该技术的浮动车交通信息采集方法得以应用实现.纽约、波士顿、东京、上海和北京等各大城市都相继研发了对应的浮动车信息采集系统, 其中以出租车为主要数据来源.本文使用的出租车行驶轨迹数据包含如下信息:出租车ID信息、触发事件、运营状态、GPS时间、GPS经度、GPS纬度、GPS速度、GPS方向、GPS有效性.其中触发事件字段值代表车辆的运营状态发生改变, 当且仅当车辆的运营状态发生改变时触发该值变化.运营状态是指车辆当前采集时间的运营状态.
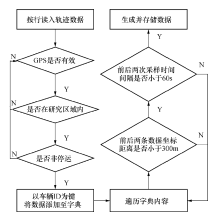
在浮动车数据处理过程中, 除了包含有常规数据清洗流程之外, 还需要结合浮动车的数据特性将离散的原始数据提取为连续的轨迹数据, 并针对连续的轨迹数据进行再次清洗, 保留满足一定采样率的数据, 保证研究使用数据的有效性.本文使用的数据采样率主要集中在9~15 s和53~57 s两个区间内, 其中小于15 s的数据所占比例大于73%, 此部分数据可作为精确提取轨迹的预备数据.在对数据进行较为详细的样本分析之后, 明确原始数据的基础属性, 可以针对数据的格式以及字段进行统一处理, 建立标准的数据预处理流程, 并依照该项标准设计数据清洗代码, 最终形成可直接用来研究的浮动车数据.
浮动车轨迹数据清洗流程见图1.
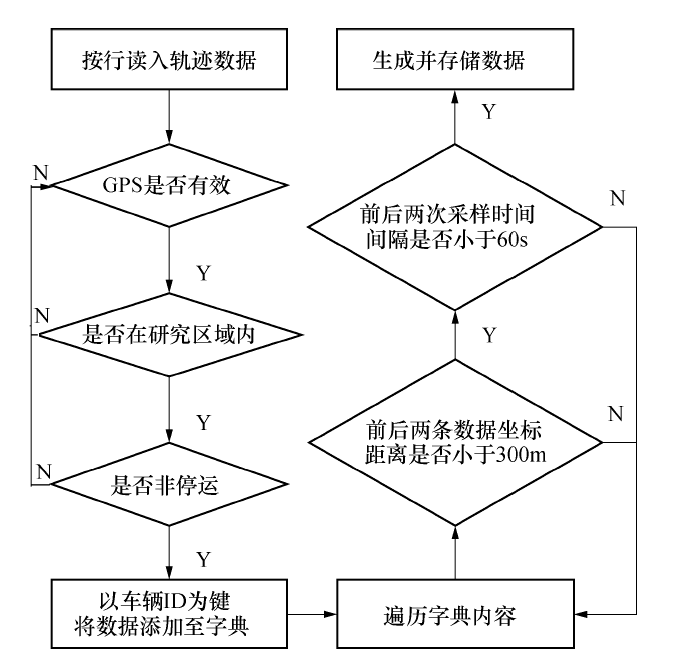 | 图1 浮动车数据预处理流程Fig.1 Flow chart of data pretreatment for floating car |
本文提出的交通网格化模型来自城市管理网格模型理论.城市管理区域可以被静态或动态地划分成具有特定大小的网格, 网格中的设施按类别进行管理, 以提高管理效率[14].虽然现在更多的研究倾向于线性地将出租车的轨迹分配给用于交通分析的道路网络, 即将浮动车轨迹与道路路径匹配后再对路网的交通状态进行研究[15, 16], 但是交通网格模型具有如下优势.首先, 允许采样率在一定范围内变化, 并且网格建模不需要复杂的道路匹配算法, 对数据的精度要求可以有一定的放宽.第二, 交通网格模型不需要精度较高的GIS拓扑地图, 仅需要大致的经纬度范围即可展开研究.第三, 网格模型可以将传统的一些数据挖掘方法重新应用到海量数据的挖掘过程中, 大大简化轨迹匹配的过程, 从而提高计算效率.
将整个平面路网切分为统一大小的网格, 每个网格中可能包含有快速路、主干道、次干道以及快速路匝道等多种等级不同方向的道路.划定网格的边长为1 km, 在该范围内, 同一进出口组合所对应的路径只有一种, 计算浮动车通过进出口的时间差就可以反映出该路径上的通行时间.因此对整个研究区域通过地图离散化, 划分为多个区域, 该区域集合记为:
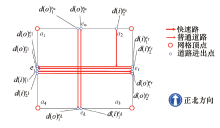
中包含有多条道路, 这些经过该网格的道路均为从与该网格相邻的网格中进入, 并向相邻的网格驶出, 进出网格的过程中, 均在空间上与网格的边形成交叉.在本节研究中, 基于这些交叉点以及这些交叉点的连通关系, 提出网格交通属性静态特征的模型建立方法.有如下变量定义:
网格
网格
网格每条边上的道路编号为
网格每条边上的道路编号为
网格内的轨迹由每条边上的进出口节点对组合进行表征:
以图2为例, 网格
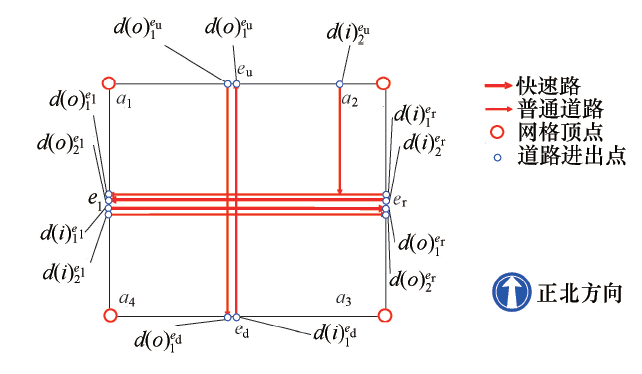 | 图2 网格中路网拓扑关系示意Fig.2 Sketch map of topological relation in middle cell network |
在一天的时间周期中, 随着时间变化, 网格中节点对之间连通的道路路况也随之变化.因此可针对每一个节点对, 按照固定切分方法, 将指定的时间长度切分为同等时长的时间切片, 每个时间切片对应一个期望的通行时间, 有如下定义:针对
式中:
针对提出的网格模型中所包含的交通属性特征, 需先提取网格中静态交通特征, 再提取网格中动态交通属性.网格静态特征主要为浮动车轨迹进入和驶出网格的位置以及进入和驶出位置之间的连通关系.首先通过网格边界轨迹的前后两个进入点, 提取轨迹与网格边界的全部交点; 然后对同一边界上的交点进行密度聚类, 提取出经过网格边界交点的核心位置及宽度; 最后通过提取同一辆车经过网格过程中驶入和驶出的节点信息, 找出有连通关系属性的节点对, 从而完成了网格中静态交通属性的提取过程.
在已有静态数据的基础上, 针对车辆通过网格节点对的前后时间, 提取时间差作为当时时间片段内该节点对的行程时间, 从而完成了网格模型中节点对动态交通属性的提取过程.
使用相对延误衡量节点对拥堵程度, 表示方法如下
式中:
我国公安部发布的《城市交通管理评价指标体系》中指出[17], 城市主干道上机动车平均行程速度小于30 km/h, 大于20 km/h时为轻度拥堵; 小于20 km/h, 大于10 km/h时为一般拥堵; 小于10 km/h时为严重拥堵.对应主干道限速为60~80 km/h, 可以对相对延误给出如下基本判定公式
针对每天的时间集合
在浮动车轨迹数据与网格化地图匹配的基础上, 构建网格模型, 将网格内特定时间片段内的浮动车轨迹数据的速度均值作为计算网格内交通运行指标的参考值, 通过聚类的方法对网格化的特大城市道路交通运行状态特性进行研究, 总结分析不同时间、空间和路网结构下的拥堵网格分布, 最终将从空间上的“ 点— 线— 面” 3个层级对交通拥堵来进行评价研究.
本节的核心任务为宏观评价交通拥堵程度和分布, 有别于第2节中从微观层面精确地提取交通运行状态信息的目的, 网格规模要按照大部分网格中包含且仅包含有一条路段的原则进行确立.
定义变量
式中:
根据定义, 当
式中:
单个网格的交通运行指数仅对独立的单个网格的交通运行状态有评价作用, 仅仅通过单个网格的交通运行指数的分析很难反映全体路网的宏观交通运行状态, 因此, 考虑通过聚类算法对网格进行数据挖掘, 将临近的交通指数较高的网格较为合理地聚集在一起.DBSCAN (Density-Based Spatial Clustering of Applications with Noise)是基于密度的聚类算法中的典型代表, 能够把具有足够高密度的区域划分为同一类, 并且聚类结果不受数据分布的空间形状影响[19].这些特征恰好符合此次研究路网中网格的特点, 因此本文选用该算法对基于网格的交通运行状态进行聚类.
当在网络中分析网格时, 将DBSCAN中的数据点重新定义为网格.首先,
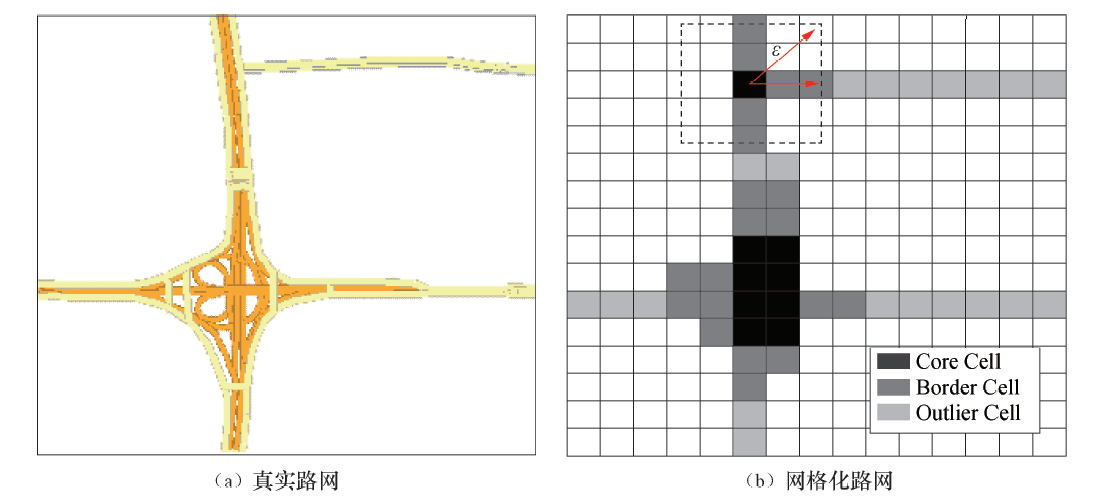 | 图3 密度聚类算法中变量定义示意Fig.3 Schematics of variable definition in DBSCAN |
最小样本量
首先, 利用ArcGIS软件制定网格模型下的宏观交通运行状态3D地图, 通过网格的高度来反映对应网格的拥堵程度, 从而发现严重拥堵区域.然后, 将全部网格的总体交通运行指数纳入DBSCAN算法中做进一步探索, 选取更加合适的
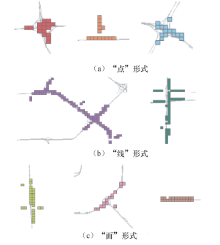
交通拥堵类从空间特征上可划分为“ 点-线-面” 3种形式.“ 点” 形式的拥堵往往发生在主干道交叉形成的平面信号交叉口, 或者是快速路与主干道连通的立体交叉口, 该类拥堵相对较为独立, 与周边其他的拥堵区域关联性不强.造成其拥堵的原因往往来源于交叉口通行能力不足, 因此在治理这类型拥堵的过程中可以从提高交叉口的几何设计, 优化交叉口信号灯配时等方面进行考虑.当“ 点” 拥堵的程度进一步提升, 就会对所处路段造成影响, 导致上下游路段的通行状态恶化, 形成“ 线” 形式的拥堵, 想要解决“ 线” 类型的拥堵, 简单地提高单点的通行能力是不够的, 需要结合当地的道路网, 应用交通诱导等方法实时地给驾驶员发送交通信息, 从而将交通需求适当平衡分布, 从源头上降低该路段的通行压力, 缓解拥堵.当相互连通的快速路的通行压力均有较大提升时, 会造成对应区域大面积拥堵出现, 这时就会出现“ 面” 形式的拥堵.3种拥堵类型如图4所示.
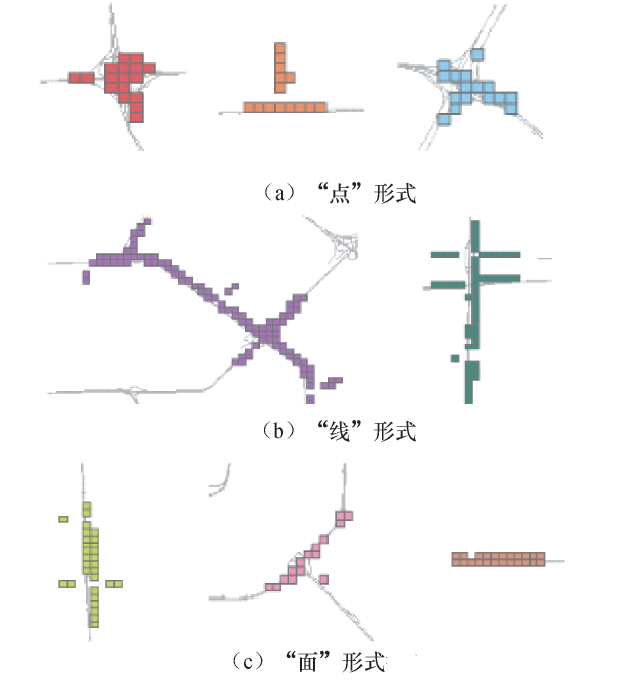 | 图4 “ 点-线-面” 拥堵类型Fig.4 Point-line-surface congestion types |
本文选取北京市16 000辆出租车2012年11月1日至11月30日一个月的轨迹数据, 研究区域为北京市五环范围内, 建立不同的网格规模, 进行交通拥堵识别和交通运行状态评价.
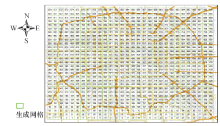
将研究区域划分为30× 30共900个网格, 并从西南方向开始编号, 如图5所示.
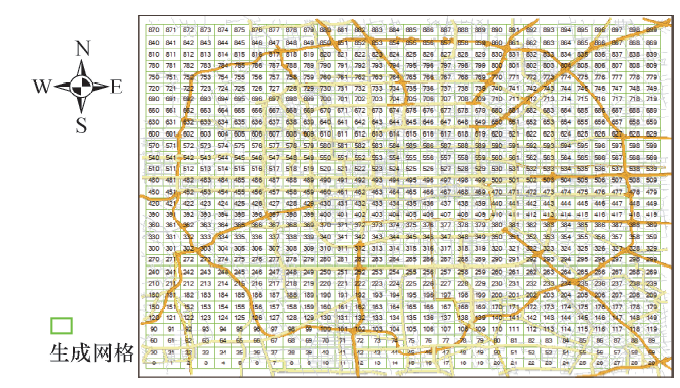 | 图5 最终确立的900个网格的示意图Fig.5 Schematic diagram of the final 900 grids |
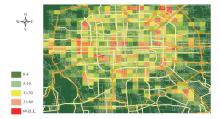
按照2.2节的网格模型属性提取方法, 对全路网进行计算, 共有19 561个节点对, 900个网格中, 共有802个网格中存在连通的节点对, 通过ArcGIS软件对每个网格内节点对的连通关系数量进行可视化展示, 如图6所示, 通过颜色由绿到红表征网格内节点对数量由少到多, 由该图可以直观地观察出北京市研究区域内各个网格内的道路网密度, 这也从侧面反映出北京市大部分中心区域承担微循环作用的支路密度不足, 需要进一步加强建设.
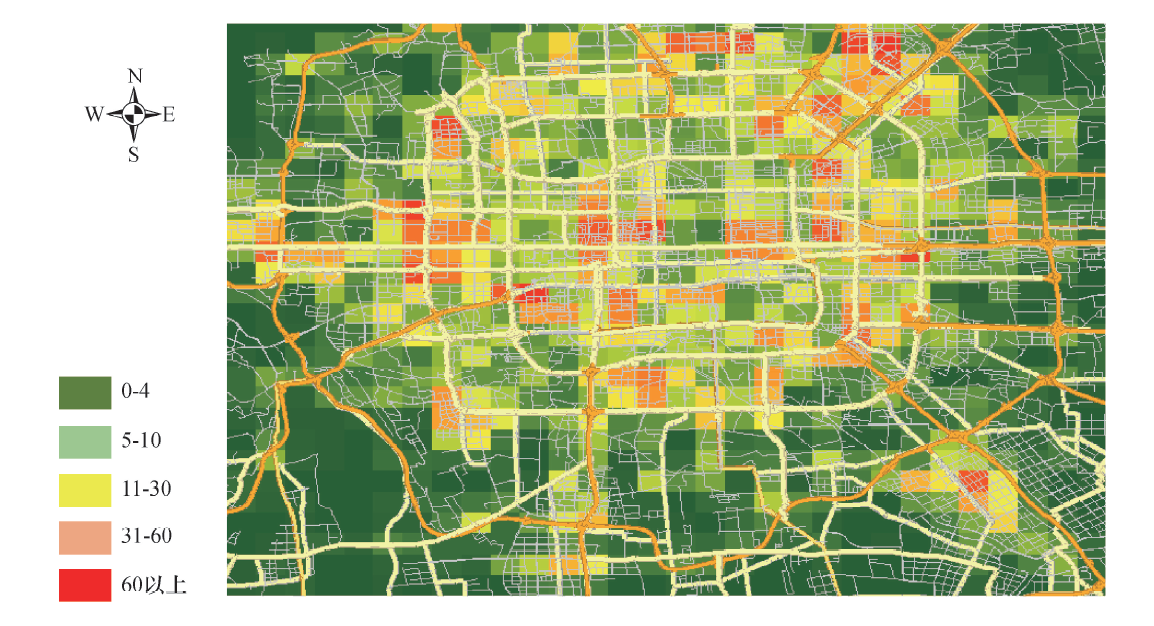 | 图6 网格中包含的连通节点对数量分布地图Fig.6 Number distribution map of connected nodes in a grid |
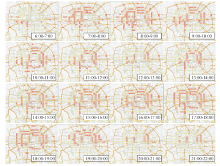
此次研究中面向的数据包含一个月的数据, 因此拥堵识别选取连续
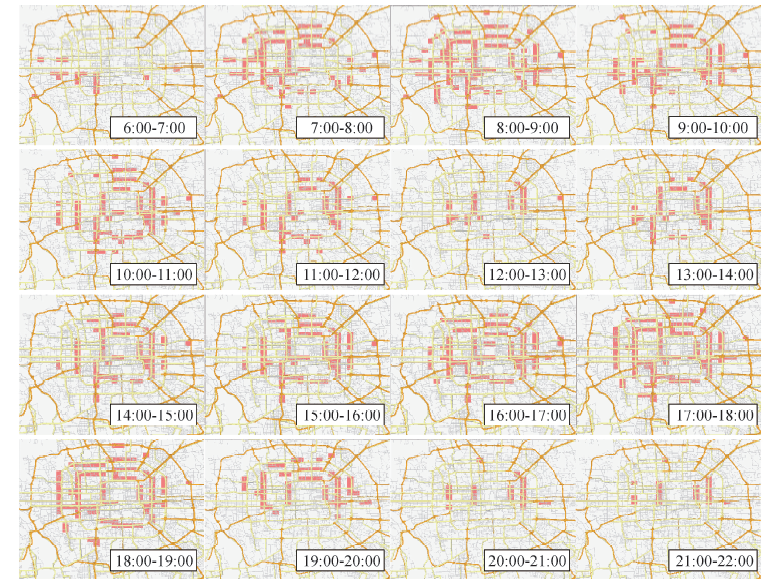 | 图7 北京市常发拥堵网格时序变化图Fig.7 Timing variation diagram of Beijing congestion grid |
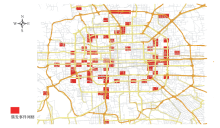
通过对全部数据进行统一处理, 提取全路网900个网格中所有偶发事件, 在此基础上, 对全路网网格中发生的事件数量进行统计, 然后通过ArcGIS软件将网格事件发生数进行可视化展示, 见图8.
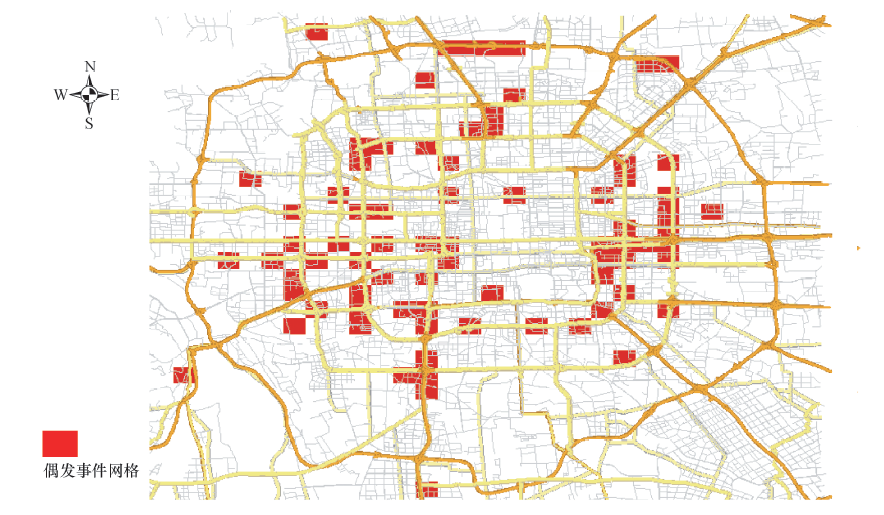 | 图8 北京市2012年11月偶发事件网格分布地图Fig.8 Grid distribution map of accidental events in Beijing in November 2012 |
从图8中可以发现环路和联络线形成交叉的网格内相对更容易有偶发拥堵事件发生; 三环路和四环路偶发拥堵事件的发生数量要远高于二环; 五环路中, “ 京藏高速” 与五环交叉处的“ 上清桥” 至北苑的“ 仰山桥” 段发生事故较多.
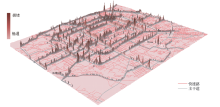
应用交通拥堵宏观评价方法对北京市五环内宏观层面的交通运行状态进行评价.按照大部分网格中包含且仅包含有一条路段的原则, 根据北京五环内路网密度, 选择100 m× 100 m左右的网格进行研究.在该尺寸规模的网格下, 将研究区域划分为300× 300个网格.得到90 000个网格独立的交通运行指数后, 生成了北京市快速路网的全月交通运行状态三维分布图9, 可以直观发现, 越靠近城市中心区域的快速路, 其对应的网格拥堵程度会越高.
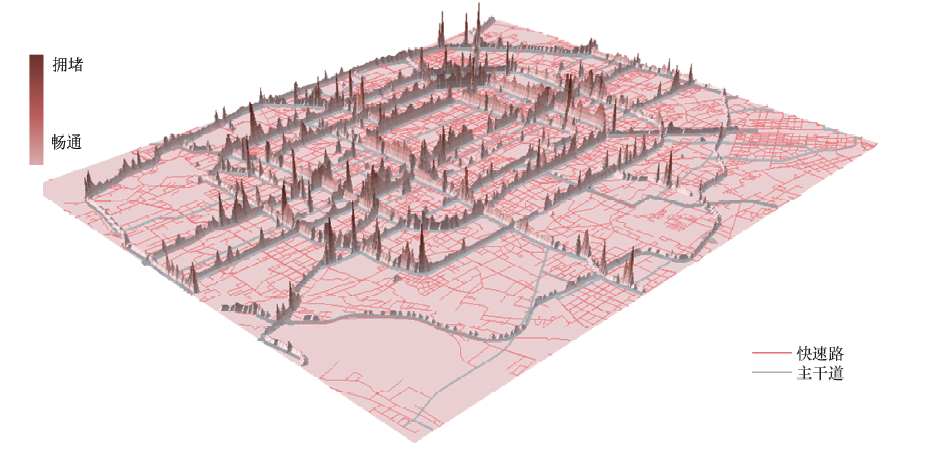 | 图9 2012年11月北京交通运行状态3D图Fig.9 3D visualization of traffic operation performance in Beijing in November 2012 |
使用DBSCAN对全体路网进行聚类, 将临近的交通指数高的网格较为合理地聚集在一起, 最终生成55个类, 如图10所示, 不同颜色表征不同的类.由55个交通拥堵集群的空间分布, 可以看出在北京道路网中, 最典型的“ 面” 类型的交通拥堵地区即为东三环、东四环与首都机场高速交叉的区域.该类型的拥堵治理较为困难, 需要分析经过该区域车辆的OD需求, 针对提取出的OD信息从公共交通、交通诱导等方面着手, 才能起到一定的治理效果.
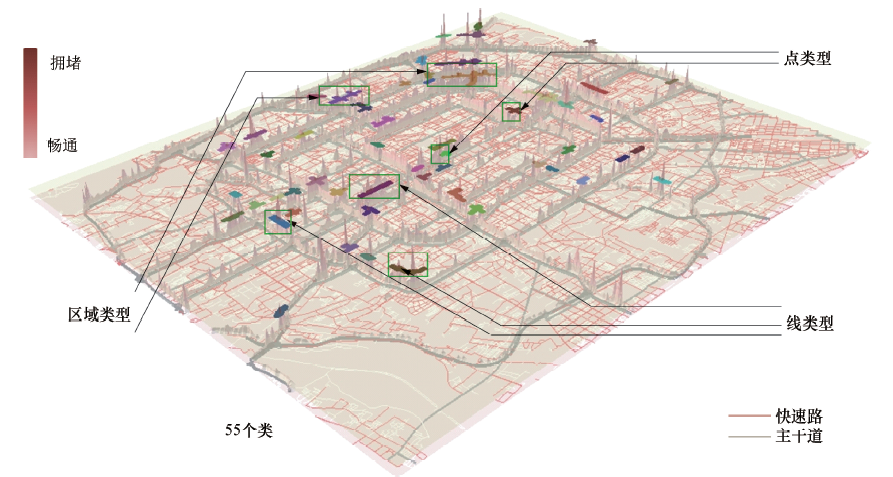 | 图10 聚类结果的3D效果图Fig.10 3D visualization of congested cells clustering result |
本文以海量浮动车轨迹数据挖掘为基础, 将北京市五环范围作为研究实例, 针对城市道路网络中拥堵识别和拥堵评价的问题, 通过建立网格模型展开系列研究.得出如下结论:
1)将城市管理理论中的网格模型应用到道路网络交通运行研究中, 从理论研究层面探索高效准确的海量轨迹数据与地图数据匹配方法.
2)对浮动车轨迹数据深入挖掘, 在区域网格化的基础上有效识别出区域的常发、偶发拥堵时空分布.回避了以往研究中将轨迹数据与路网矢量数据进行匹配的过程, 提高了计算效率, 达到了面向海量数据的实时计算要求.
3)研究网格化的特大城市道路交通运行状态特性, 总结分析不同时间、空间和路网结构下的拥堵网格空间分布特征, 提出特大城市拥堵区域的空间特征基本可以划分为“ 点— 线— 面” 3个层级, 从而实现宏观层面的城市交通运行状态评估.
研究结果能够帮助交通管理部门找到相应的交通运行状态不佳的区域, 对区域范围能够给出较为明确的定位, 且对范围内拥堵的程度有一定的反映, 从宏观的角度对交通拥堵情况进行评估.但在构建面向网格模型的拥堵识别中, 仍然使用了传统的依靠速度判定城市道路严重拥堵路段的标准, 该标准对拥堵因素考虑不够全面, 可能导致拥堵识别结果出现误差.在后续的研究中可以对基于轨迹数据的拥堵识别标准进一步探索, 进而提高基于网格模型的交通拥堵快速识别的准确率.同时, 未来可根据轨迹数据的精度、采样频率以及研究目标, 提出一套较为规范的网格规模划分标准.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|