


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于DHT的数据中心网络租户隔离技术
[孙延涛a  , 位月
, 位月b , 耿岚岚b , 贾泽群b , 石贺b ]
, 位月|
|


第一作者:孙延涛(1975—),男,山东枣庄人,副教授,博士,博士生导师.研究方向为云计算,email:ytsun@bjtu.edu.cn.
多租户技术是云计算中一种软件架构技术,旨在解决多用户环境下软、硬件资源共享的问题,并且确保各用户间数据的隔离性.目前,多租户技术在如何突破子网限制,实现虚拟机 IP 地址与所在子网位置分离、支持虚拟机迁移等方面存在诸多问题.针对上述问题,提出了一种新的面向数据中心网络的多租户隔离技术.该技术利用一致性哈希算法和分布式环形哈希表技术,将虚拟机信息保存在位置解析器上,并利用位置解析器的位置解析功能实现租户间的相互隔离、租户内虚拟机的相互通信及虚拟机的迁移.该技术与具体路由实现方式无关、对虚拟机完全透明、无需部署额外的服务器,其成本低,鲁棒性好.本文利用OPNET仿真软件对多租户隔离技术方案进行可行性验证及性能分析.仿真实验表明:该技术能够实现租户之间的通信且能够保证良好的网络性能.
Multi-tenancy technology is a kind of software architecture technology in cloud computing. It aims to solve the problem of sharing the same hardware and software resources in multi-user environment and ensure data isolation among users. At present, there are many problems in multi-tenancy technologies such as how to break subnet restrictions to separate IP addresses of virtual machines from their subnets, and how to implement migration of virtual machines. To address above problems, this paper proposes a new multi-tenancy isolation technology for data center networks. The technology uses a consistent Hash algorithm and a Distributed circular Hash Table(DHT) technology to store the information of virtual machines in location resolvers. The technology supports isolation of tenants,the communication between the virtual machines within a same tenant and the migration of virtual machines.This technology does not depend on specific routing methods, not require extra servers and is transparent to virtual machines, so it takes low cost and has good robustness. At the end,we analyze the feasibility and performance of the multi-tenant solution by OPNET simulation software.Simulation experiments show that the technology can achieve communication between tenants and ensure good network performance.
随着云技术的不断发展, 数据中心架构逐渐由传统架构向云架构方向转变.作为云计算和大数据分析的基础设施, 数据中心网络得到了学术界和工业界的广泛关注.目前, 数据中心网络在路由技术[1]、网络安全、云无线接入网[2]、多租户技术等相关领域都开展了大量的研究工作, 其中, 多租户技术是本文关注的重点.
EC2、阿里云等面向公众提供云计算服务的大规模数据中心多租户网络承载了大量的租户, 通常情况下, 租户网络之间不需要相互通信.因为出于对网络安全的考虑, 数据中心的管理者希望租户网络之间在逻辑上相互隔离, 并且针对不同用户提供一定服务质量保证[3].因此, 多租户技术应运而生, 该技术旨在实现多用户之间的资源共享和数据隔离.
目前, 数据中心网络中多租户的划分一般使用虚拟局域网(VLAN)技术, 每个租户网络组成一个VLAN, 不同VLAN之间在逻辑上实现隔离[4].但是采用VLAN解决数据中心租户隔离问题还存在着一些问题, 例如VLAN数量不足、VLAN配置复杂等.针对这些问题, 业界提出了很多新的技术协议.
虚拟可扩展局域网(VXLAN)是目前获得业界最广泛支持的协议.思科、博科和VMware都支持该协议.VXLAN技术采用隧道封装技术实现在三层网络基础上建立二层网络隧道, 从而实现跨地域的二层互连[5].VXLAN通过源学习方式将虚拟内存(VM)的MAC地址与Vxlan隧道终点(Vxlan Tunnel End Point, VTEP)的IP地址相关联, 并在路由过程中采用MAC in UDP方法依靠VTEP实现单播与广播报文的转发[6].由此而知, 在VXLAN网络中VTEP节点的负担将会很大, 可能会影响到路由器的转发速率, 进而影响整个网络的性能.
NVGRE协议是与VXLAN协议相似的隧道协议[7], 与VXLAN 协议不同的是, NVGRE借助通用路由封装协议(GRE)对报文进行封装[8], 这导致NVGRE不能兼容传统的负载均衡方案.NVGRE以一种更灵活的方式进行广播, 不需要依赖泛洪和IP组播进行学习, 但是需要依赖硬件/供应商, 对硬件设备的要求较高.
文献[9]提出了一个基于多链接透明互联(TRILL)的多租户网络架构, 主要通过TRILL协议实现桥接和路由并确保网络的可扩展性和管理简单化.文献[10]提出了HostVlan多租户技术来改善广播问题.文献[11]提出了NetLoad方法实现多路径路由和负载均衡, 但计算量大, 处理复杂, 对网络变化的适应性差, 并且需要修改终端设备.文献[12]提出SEATTLE方案, 该方案通过链路状态路由协议在交换机之间建立路由, 并采用DHT(分布式哈希表)实现虚拟机全网迁移.该方案对网络结构没有要求, 应用范围广, 适用于较大规模的数据中心网络, 但是在该解决方案中, 虚拟机需要完成MAC地址向主机的映射, 路由过程对二层协议不透明.
基于上述研究, 本文作者提出了一种基于DHT的多租户隔离技术.和现有方法相比, 该技术实现简单、开销小、可靠性好, 支持虚拟机全网迁移, 适用于大规模数据中心网络.
DHT的多租户隔离技术的主要思想是:在网络中部署多个位置解析器, 并通过分布式哈希算法将租户的虚拟机位置信息存储到位置解析器上; 节点之间相互通信时, 源节点首先查询位置解析器以获得目的节点的位置, 然后采用IP in IP技术封装IP报文实现路由; 每个租户网络分配一个唯一的ID(Tenant Network ID, TNI), 在接入交换机上根据TNI限制不同租户网络相互通信, 实现租户隔离.
此外, 本方案采用租户网络ID进行地址映射, 同一租户网络的虚拟机位置信息存储到同一个位置解析器上面; 本方案对广播报文的处理过程进行了优化:将ARP广播报文处理成单播报文, 把租户网络内部的其他广播报文, 根据发送频率自适应地转化为组播或单播报文.
和VLAN等传统技术相比, 本方案增加了很少的额外开销:1)方案利用IP over IP技术封装原始报文, 报文增加了20个字节报文头部开销; 2)在路由过程中, 交换机需要对于业务流的首个报文解析目的节点的位置, 增加了一点时间开销.
和现有技术相比, 该方案主要优点如下:
1)支持支持虚拟机全网内迁移, 虚拟机迁移后其IP地址保持不变.本方案分离了VM的IP地址和其所在子网位置的关联联系, IP地址只是用于标识一台虚拟机, 不再作为目的地址参与路由选择.
2)不依赖于具体的路由协议.方案采用IP in IP技术封装原始的IP报文, 可以工作在任意路由协议上面.
3)同一租户网络的虚拟机位置信息存储到同一个位置解析器上面, 方便对租户网络进行管理和易于实现租户网络内组播.
4)对广播报文进行优化, 避免了大规模网络里广播报文洪泛造成的网络拥塞.
本文技术方案主要从控制和转发两个层面进行分析.控制层面包括设备学习和位置解析两部分, 主要完成位置解析工作; 转发层面负责路由功能, 包括单播路由和广播路由两部分.
本技术利用DHT将VM的位置信息分散地存储到DCN中的交换机上面, 这些交换机称为位置解析交换机(即位置解析器, 简称为解析交换机).由于解析交换机的位置会影响位置解析的通信路径长度, 同时考虑到交换机的负载能力, 本方案允许只选择部分交换机作为位置解析交换机.比如, 在Fat-tree网络中, 选择所有的核心交换机作为位置解析交换机.位置解析交换机由网管人员手工配置.
为了计算存储目的VM地址的解析交换机, 接入交换机需要学习整个网络中所有的位置解析交换机.解析交换机采用受限扩散的方式在网络中发送设备公告报文来公告自身.在受限扩散中, 一台交换机只有在接收到新的解析交换机的公告报文时才向其邻居节点转发该公告报文并将该解析交换机的信息存储到本地数据库中, 否则, 直接丢弃该报文.受限扩散方式保证了每台交换机都可以学习到网络中的所有位置解析交换机, 并且每台交换机对学习到的解析交换机信息只会扩散一次, 因而可以避免报文循环转发引起的网络风暴.
接入交换机除了需要学习网络中所有的位置解析交换机, 还需要检测连接到该交换机的所有VM.通常情况下, 每个VM在启动时会发送一个Gratuitous ARP消息.利用该消息, 接入交换机可以获得VM的TNI、IP和MAC地址等信息.如果VM启动时不发送Gratuitous ARP, 服务器的Hypervisor需要发送一个消息给接入交换机, 通知接入交换机该VM的TNI、IP和MAC地址.
在本技术方案中, 采用VM所连接的接入交换机来表示一个VM的位置.接入交换机获得一个VM的相关信息后, 通过Hash算法F
式中:H是一个常规的Hash函数.D(x, y)是在H的环形Hash空间上沿逆时针方向从x到y的距离.F在H的Hash空间上把k映射为距离最小的解析交换机的ID.F函数需要对比k和每个交换机的Hash值.为了提高F的计算速度, 在实验中将所有交换机的Hash值组织成一个平衡二叉树.
在位置解析器上, 每个VM存储如下三元组信息:< VM-IP, TNI, AS-IP> .VM-IP表示该VM在租户网络中的IP地址, TNI表示该VM所属租户网络的ID, VAS-IP是该VM所连接的接入交换机的IP地址.
本技术借鉴SEATTLE中提出的采用DHT解决虚拟机迁移问题的思想, 提出基于DHT的多租户隔离解决方案.在SEATTLE中, DHT中的Hash函数H采用VM的IP地址作为输入参数, 而本文的Hash函数H采用VM的TNI作为输入参数.采用TNI作为输入参数具有以下好处:
1)同一个VLAN下的VM地址映射到一个Sr, 便于对VM进行管理.比如, 数据中心管理系统可以查看每个VLAN下的VM.
2)便于实现VLAN组播.本方案使用租户网络ID进行Hash, 可以将同一租户网络的VM映射到同一位置解析交换机上.租户网络内进行广播时, VM首先将广播报文发送至位置解析交换机, 位置解析交换机根据源地址和广播地址将报文组播到该租户网络内.利用TNI能够快速高效地在一个租户网络内实现报文广播.
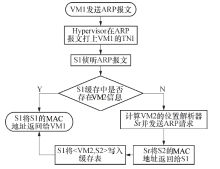
本方案设计了一个和传统以太网完全兼容的路由过程, 地址解析过程对主机完全透明.在传统以太网中, 两个主机之间相互通信, 源主机会把发送数据封装在一个以太网报文中, 然后发送出去.在封装以太网报文时, 如果不知道目的主机的以太网地址(MAC), 会首先发送一个ARP广播报文请求目的主机的MAC地址.如果接入交换机划分了VLAN, 报文进入交换机后还会被打上一个VLAN标签.本方案对ARP过程做了优化, 把ARP广播报文转化为一个单播报文, 该过程对主机完全透明.假设VM1(SRC)发送ARP报文来请求VM2的MAC地址, 具体过程如图1所示.
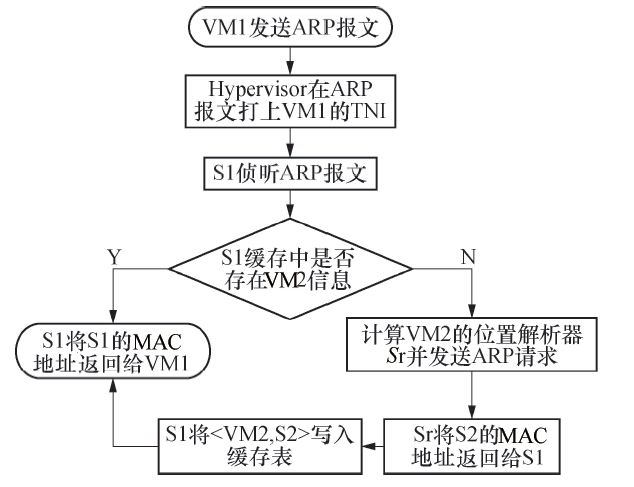 | 图1 ARP请求的处理过程Fig.1 Process of ARP |
由图1可知, 在ARP请求的处理过程中, S1并没有把VM2的MAC地址返回给VM1, 而是把S1自身的MAC地址返回给VM1.这样做的好处是可以将MAC地址限制在一个交换机范围内, 减少了MAC地址冲突的可能性.虽然每个物理网卡的MAC地址是唯一的, 但是, 由于每台服务器可能被虚拟出多个VM, 因此需要为每个VM虚拟出一个网卡, 保证虚拟网卡的唯一性可能会存在一定的困难.
由于本技术解除了VM的IP地址和其所在子网位置的关联, 因此VM的IP地址不能应用于网络路由.为此, 我们采用IP in IP隧道技术使VM的报文穿过数据中心的骨干网络.因此, 本技术无需对数据中心网络的路由做任何改动, 可以支持任何种类的路由方式.假设VM1发送数据给VM2, 报文穿过数据中心骨干网络的方法如图2所示.
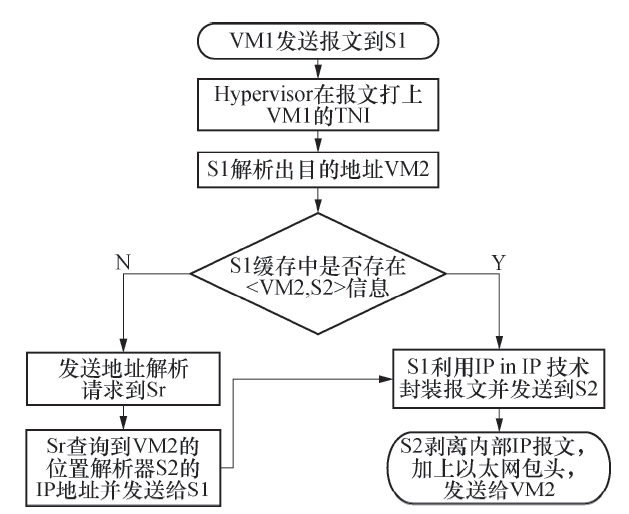 | 图2 解决方案的路由过程Fig.2 Routing process in the solution |
上述路由过程表明, 路由的查询和建立过程依赖于租户网络ID, 在Hypervisor给报文打上VM1的租户网络ID后, 该报文只能在同一租户网络内传输, 从而实现了租户网络之间的隔离.而且, 整个报文转发过程对虚拟机完全透明, VM1认为VM2和它位于同一个子网内.因此不需要对虚拟机做任何改动.
本技术把相同TNI的VM通过DHT映射到同一个位置解析交换机上, 其目的是为了实现高效的租户网络内广播.在地址映射过程中, 接入交换机把其连接的每个VM地址信息通过专门的报文存储到位置解析交换机上.在地址映射过程中, 每个租户网络以位置解析交换机为根构建一个组播树.当VM需要在租户网络内进行广播时, 广播报文首先发送至位置解析交换机, 然后组播到这个租户网络.一个大的数据中心可能支持数万个甚至更多的租户网络, 为了减小组播路由表的规模, 采用超时机制, 在一段时间内没有组播报文发送时, 相关组播条目自动从组播路由表中清除.当一个广播报文到达位置解析交换机时, 如果其组播树已经被清除, 则重新计算并构建组播树.这一措施可以在很大程度上减少组播表的规模, 特别是在广播报文非常少的情形下.
运用超时机制减少组播路由表的大小不仅节省了内存空间, 还大大提高了路由效率, 在组播路由过程中控制路由表的规模可以减少路由查找时间, 提高组播效率.此外, 启用超时机制可以保证组播路由表的时效性.
本实验基于Fat-tree网络[13]对交换机的位置解析能力进行了模拟测试, 并利用OPNET 16.0仿真软件[14]搭建仿真场景对本文方案进行可行性验证和性能分析.
在48端口交换机组成的Fat-tree网络中, 最大可以容纳27 648台服务器.假设1台服务器虚拟成4个虚拟主机, 整个网络中可以110 592个主机.网络中总计有576台核心交换机.因此每台交换机平均需要承担192台虚拟主机的解析.这一数量的解析任务对路由器的性能影响是非常小的.通过计算机做了模拟测试.该计算机CPU为Intel i7-2640M, RAM 8 GB.在实验中, 使用6台设备和1台位置解析器模拟位置解析过程:在每台设备中创建20个线程, 每个线程连续向解析器发送位置解析请求; 位置解析器负责接收报文并进行位置解析.经统计, 该过程每秒钟可以产生超过3万次的任务请求, 而该计算机的CPU利用率为72%~80%之间.实际上每台交换机的平均任务负载在200个左右, 远小于模拟实验中的负载量, 所以路由器具有足够的位置解析能力.
利用OPNET仿真软件对技术方案进行验证和分析.为了实现本文技术, 首先对路由器模型进行如下修改:1)指定核心交换机为位置解析器; 为地址解析交换机增加Hash模块(如图3左边的红圈标记处)来处理接入交换机发送的保存有虚拟机信息的哈希报文并将虚拟机信息保存到位置解析器中; 修改标准路由器模型的ARP模块(图3右侧的红圈标记), 实现位置解析功能和路由过程; 修改后的路由器模型如图3所示.
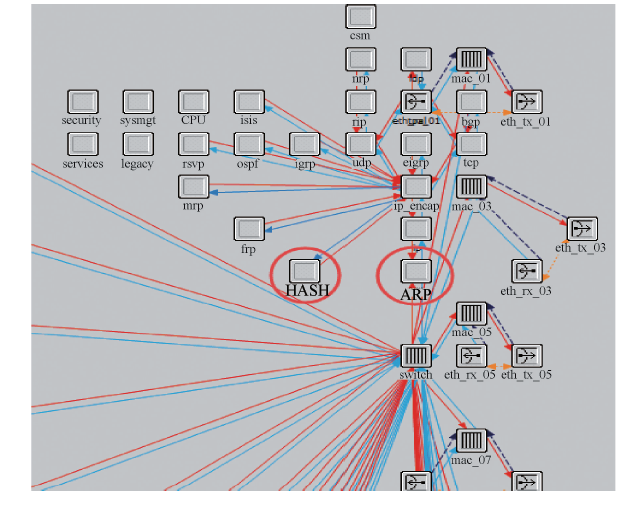 | 图3 修改后的路由器模型Fig.3 Modified router model |
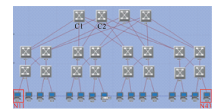
基于上述路由器模型, 本实验搭建由20台路由器16台服务器组成的3层Fat-tree网络拓扑, 具体网络结构如图4所示.
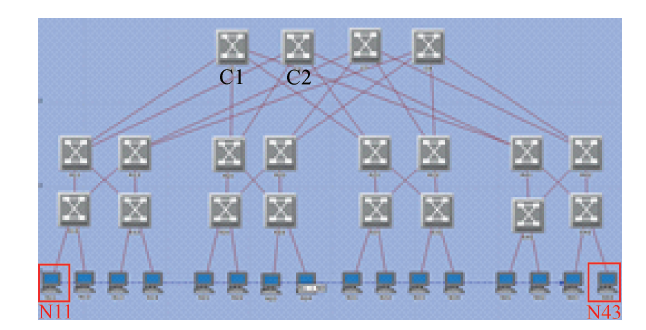 | 图4 仿真拓扑图Fig.4 Simulation topology |
为了验证本文技术的可行性, 在拓扑中的两个虚拟机之间(以N11和N43为例)创建IP单播数据流, 该数据流的发送速率为每秒12个报文.图5中蓝色虚线即为该单播报文转发过程.其中C1为N43的位置解析器, 虚拟机N11从C1获取N43的位置信息, 并发送单播报文; 单播报文经图中路径到达目的虚拟机N43.该过程说明本文提出的解决方案可以实现单播路由通信功能.
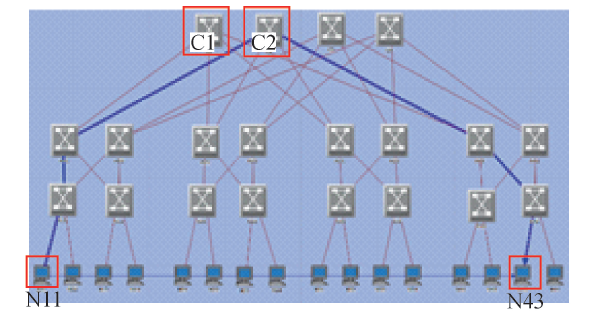 | 图5 单播报文转发过程Fig.5 Forwardingprocess of unicast packet |
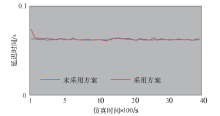
为了分析本技术对网络时延的影响, 本节分别采用多租户隔离方案和不采用方案进行实验并获取端到端时延结果, 端到端时延如图6所示.
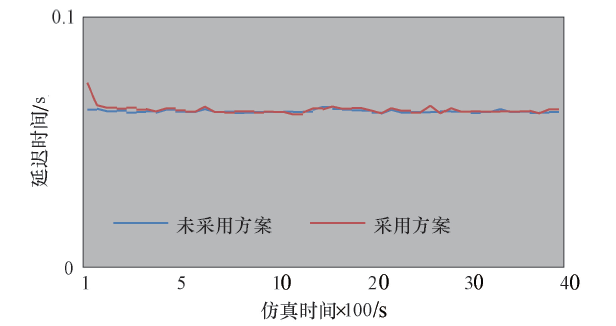 | 图6 端到端时延对比Fig.6 Comparisonsof end-to-end delay |
由图6可知, 未采用方案时的网络时延保持在62 ms左右, 使用本解决方案在仿真一开始产生75 ms的时延, 但之后迅速减小到62 ms左右, 由此可知, 采用本文隔离方案会在实验一开始造成13 ms的延迟增长, 但时间很短.这是因为本文方案通过地址解析器实现路由, 两台虚拟机进行第1次通信时, 源虚拟机需要借助位置解析器来解析目的虚拟机的位置信息, 此过程会造成了端到端延迟的增加.而在第1次路由时, 位置解析器将目的虚拟机信息返回给源虚拟机, 源虚拟机缓存该信息, 两台虚拟机再次进行通信时源虚拟机缓存中已存在目的节点信息, 可以直接通信, 不会造成额外的时间延迟.
1)针对数据中心网络中的多租户隔离问题提出了一种基于DHT的面向数据中心网络的多租户隔离技术.该技术通过引入租户TNI码隔离租户网络, 并利用位置解析交换机实现租户网络的通信, 在此基础上实现了租户内的虚拟机任意迁移.利用OPNET仿真软件进行实验, 验证了该技术的可行性, 两虚拟机可以通过该方案进行通信.
2)实验对其性能做了分析, 该技术在虚拟机首次通信时造成了13 ms的网络时延增长, 此后对网络试验没有影响.除此之外, 本文还提出了租户网络内的广播解决方案, 下一步工作中将完成相关实验对该方案进行验证.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|