{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于用户与网络行为分析的主机异常检测方法
[郭志民1  , 彭豪辉
, 彭豪辉2 , 牛霜霞1 , 邵坤3 , 吕卓1 , 王伟2 ]
, 彭豪辉]
|
|


第一作者:郭志民(1977—),男,河南南阳人,高级工程师.研究方向为信息安全.email:guozhimin@ha.sgcc.com.cn.
当前针对主机的攻击手段越来越复杂,各种新型攻击出现得越来越频繁,使得针对主机的异常检测变得非常重要.异常检测可以检测未知攻击,并且可以检测内部威胁,成为了网络与系统安全研究的热点之一.已有的异常检测研究中,基于网络流量等单一的信息源进行异常检测的方法容易被攻击者所规避且检测率低.本文提出通过多种信息源建模并进行异常检测,分别对网络行为与用户行为进行分析,使用 K最近邻( K-NN)分类算法得出每种行为的异常值,通过加权处理得出总体异常值并将其作为异常检测的判断标准.选取了17名用户进行实验,实验结果表明:在误报率为2.9%的情况下,利用多信息源检测模型能够检测出单一信息源检测模型未能检测出的异常,检测率达到100%.
Host borne attacks have become more and more complicated. As novel attacks appear more and more frequently, host-based anomaly detection becomes very important. Anomaly detection is able to detect unknown attacks as well as internal threats. It thus has become a widely studied topic in the field of network and system security. Most existing anomaly detection studies are based on a single source of information such as network traffic, which can be easily bypassed by attacker, resulting in a low detection rate. This paper proposes to establish a multi-source model to carry out anomaly detection. We analyze user and network behavior individually, and obtain their anomaly scores with K-Nearest Neighbor ( K-NN)algorithm. The overall anomaly scores used for anomaly detection are finally formed with weights of these two behaviors. The experiments selected 17 users for testing and the results show that, in the case of false positive rate of 2.9%, the multi-source model can detect anomaly that single-source model cannot, and the detection rate reaches 100%.
当前针对计算机的各种攻击层出不穷, 虽然使用基于特征分析的攻击检测方法能对部分攻击手段进行预警, 但是随着攻击手段越来越多样化, 内部威胁愈演愈烈, 计算机仍将承受很大被攻击与渗透的风险.异常检测不仅能检测未知攻击, 也能用于检测内部威胁, 因此针对主机的异常检测系统愈发受到关注, 异常检测的关键是通过将过去观察到的用户正常行为与用户当前的行为特征进行比较, 如果两者的偏差足够大, 则说明发生了异常, 并向管理员提出警告.
异常检测已有一些相关的研究工作, 比如运用击键动力学作为主机异常检测的信息源, 主要通过将击键特性应用于异常检测来识别用户.文献[1]以用户在输入密码时区分大小写字母的按键习惯及确认密码的输入习惯(Enter or Mouse Click)为特征, 利用模糊逻辑中的隶属函数进行异常检测, 达到识别用户的目的.文献[2]对七类应用于静态用户口令的击键动力学测试数据集进行了总结归纳, 并描述了这些数据集的应用场景.文献[3]研究了当输入密码有误并进行纠正的这一过程对应用击键动力学进行用户认证时所造成的性能影响.
系统调用、命令序列及CPU状态信息等也是进行异常检测的重要数据源.当数据源是高维数据时, 需要对输入数据进行有效降维, 文献[4, 5]分别应用主成分分析(Principal Component Analysis, PCA)和非负矩阵分解(Nonnegative Matrix Factor)处理高维数据, 大幅度降低异常检测的时间复杂度.以系统调用或命令序列为数据源的异常检测中, 每条数据并不是毫无关联, 而是存在某些逻辑递进关系.文献[6, 7, 8]分别通过挖掘系统调用的先后顺序、不同时间间隔内系统调用的频率、多条命令序列在整体命令序列中出现频率为特征, 实现异常检测.用户行为对程序运作起到很大影响, 文献[9, 10]从用户行为角度出发, 通过将用户行为与程序行为进行关联, 结合模糊逻辑, 实现用户行为异常检测.
网络异常检测是异常检测中一个重要的分支, 建立正常网络流量行为模型后, 通过待检测流量与正常流量的偏差值来考察是否发生异常.文献[11, 12]分别从检测方法类别和性能评估标准的角度出发, 对现有的网络异常检测研究现状进行分析.
对于大数据环境下的网络流量实时异常检测, 首先数据处理速度是衡量系统性能的重要指标, 文献[13, 14]分别提出利用范本提取(Exemplar Extraction)提高实时异常检测系统对大规模数据的处理效率; 其次需要防御大规模人为伪造数据对异常检测造成的影响.文献[15]提出一种针对智能电网控制系统虚假数据注入的分布式异常检测技术.正常网络模型的准确度是网络异常检测的核心, 保证构造的网络模型精准描述网络环境是一项重要的研究内容.文献[16, 17, 18]分别从自适应入侵检测框架、遗传算法、杜鹃搜索算法结合模糊逻辑的角度出发, 研究网络异常检测.
K-NN是一种简单且易于实现的分类算法, 因此广泛应用于异常检测中.文献[19]提出一种运用自组织映射结合K-NN算法对电子健康监测设备系统进行异常检测的方法.文献[20]利用网络流量数据包的7类特征对分布式拒绝服务(Distributed Denial of Service, DDOS)攻击进行检测, 并使用K-NN算法对含有DDOS攻击的数据包进行分类.
使用K-NN的异常行为检测方法有利于学习用户/系统或网络行为, 挖掘使用模式, 识别新实例, 并借助学习经验自动改进, 对于识别异常状态、非法行为等非常有效.基于击键动力学、命令序列、网络流量的异常行为检测模型, 它们都只是通过分析单一的信息源来达到异常检测的目的, 如果异常来自于其他未被检测的信息源, 那么异常检测模型将失效.此外, 单一信息源无法很好地刻画出用户行为, 导致检测率低下.
为了解决上述问题, 本文作者综合利用网络与用户行为作为信息源, 针对每种单独的信息源建立一个子模块, 每个子模块为当前的系统状态进行单独评估, 最后将各个子模块的评估结果进行加权汇总, 得出一个综合异常度的评估结果.另外, 在已有的研究实验中所使用的样本数据大都来源于国内外学校或者研究机构提供的样本数据, 或者需要专门针对某个工作站进行大量数据采集, 而本文中所涉及的数据采集工作在日常办公的实验室内的计算机上就可进行, 且不影响正常使用, 因此采集的数据更加符合实际情况, 间接地提高了对内部威胁的检测率.
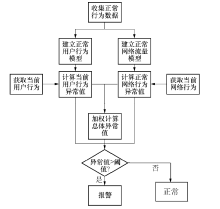
该模型由两个子模块组成, 分别是用户行为模块和网络流量模块, 分别负责收集当前计算机用户的击键信息和网络流量信息, 以及偏差值计算.模型总体架构如图1所示.
 | 图1 总体架构Fig.1 General framework |
1.2.1 数据采集与特征提取
该子模块采集正常用户键入特定双键的时间信息, 并从中找出出现频率较高且具有代表性的双键组合, 并对这些双键组合的时间信息进行处理建模, 然后将当前用户击键产生的时间信息经相同处理后与之对比, 求出偏差值.
该模块对于每一个双键组合记录:第1个键按下的时间t1, 松开的时间t2; 第2个键按下的时间t3, 松开的时间t4, 再由这4个时刻计算出一个特征向量
使用a来描述用户击键行为特征.对于一个双键组合产生的时间信息中, 定义只有当第1个键松开到第2个键按下的时间不超过一定的时间间隔T时, 才是合法双键组合, 即|t2-t3|≤ T, 此处的T取1 s.
1.2.2 用户行为异常检测
本文作者采用单类K-NN计算偏差值, 它是一种分类与回归方法, 区别于一般的K-NN, 它将训练数据集中的所有实例只划分成一个类别.分类时, 对新的实例, 根据其K-NN个最近邻的训练实例的类别, 通过计算距离等方式进行预测该实例是否属于这个类别.算法最终只有属于该类别和不属于该类别两种结果.
单类K-NN实际上利用训练数据集对特征向量空间进行划分, 并作为其分类的模型.对于这个模型, 每个训练的实例点都属于同一个类, 这相当于将整个特征空间分成两个子空间.将训练数据的实例分成一个类别, 标记为正常类.通过预测不属于该类的所有实例, 将其界定为异常类.
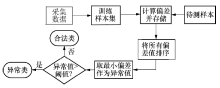
单类K-NN的一般步骤是:为训练数据建立单类模型, 选取阈值, 检测实例, 界定类别.具体步骤如图2所示.
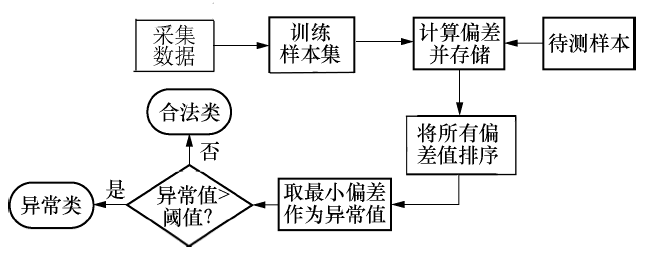 | 图2 单类K-NN工作流程Fig.2 Single class K-NN workflow |
具体到本模块, 将实时采集的时间信息转换为a, 设为b, 再计算b与正常模型当中所有向量的欧式距离, 取其中最小的两个距离的平均值, 设为W, 设最终异常值结果为V, 报警阈值为C, 递增阈值为D1, 递增梯度值为E1, 递减计数器为COUNTER, 递减阈值为D2, 递减梯度值为E2, 采用如下算法计算V.
V=0; COUNTER = 0
while True:
if V> =C:
报警
V = 0
else:
if W > = D1:
V = V + E1
else:
if COUNTER > = D2:
V = V-E2
COUNTER = 0
else:COUNTER = COUNTER+1
return V
其中阈值D1、D2和梯度值E1、E2可根据实际情况进行调整.
该子模块实现对用户上网流量的实时监测.当用户在操作计算机, 有浏览网页或者其他能产生网络流量的行为时, 该模块能够对进出本机的流量进行监控:从中提取流量特征, 接着利用提取的特征组成特征向量, 并与合法用户的流量模型对比, 最后输出当前用户行为与合法用户行为的偏差值.
1.3.1 特征选取
首先需要收集以天数为单位的正常用户的网络流量数据包, 在每天的数据流量中又以T间隔为单位, 分割数据包.对于采集的数据包, 提取出源 IP、目的IP、源端口、目的端口、时间戳, 找出所有以本机IP为源IP的数据帧, 计算出数据包的个数, 通过运输层目的端口来查询应用层协议, 统计出各个应用层协议出现的次数, 利用http数据包头统计出用户经常访问的网站, 组成样本的特征向量
式中:e1为T内数据包个数; e2为T内各应用层协议出现的次数; e3为T内用户使用http协议经常访问的网站.b中的3个属性值代表网络行为状态.在正常情况下, 这3个属性值会处在一个合理的范围内, 对于实时采集T 内的流量对应向量bt:如果b与bt的偏差不超过一定阈值, 那么说明bt的3个属性值在合理的范围内, 即bt代表一种正常状态.反之, 若偏差超过阈值, 则说明bt 的3个属性值不在合理的范围内, 即bt代表一种异常状态, 此时检测出异常.
1.3.2 网络流量异常检测
1)取b中前两类特征构成子向量
设有A1, A2, …, AN 代表连续N天内N个特征向量矩阵, 在特征向量矩阵中, 每一行表示当天内某个单位时间间隔T 内的流量所对应的特征向量.对于测试数据中代表某个单位时间间隔内的流量对应特征向量 b', 取出b' 中的前两类特征构成向量bt', 计算出 bt' 与矩阵Ai 中每个行向量的欧式距离.最后, 应用单类K-NN算法, 对应于每个特征向量矩阵, 取得其中最小的距离值Ci, 得到对应N个最小值, 将这N个值按升序排列, 取前 d 个, 再求出平均值M, 作为第1阶段异常值.
2)利用样本的特征向量b中最后一类特征, 统计出用户经常访问的网站, 构成一个集合S, 接着统计出实时抓取的流量中当前用户访问的网站, 构成一个集合H, 对于之前计算出的偏差值M, 设定一个阈值U和一个梯度值R, 使用如下算法计算出最终异常值.
for h in H:
if h also in S and M > = U:
M = M - R
else:
M = M + R
return M
其中阈值U与梯度值R可按照实际情况进行调整.
分别从用户行为模块和网络行为模块得到两个异常值, 设为X 和 Y, 如果总体异常值为V, 那么定义
其中:α 和β 是加权参数, 分别代表用户行为模块与网络行为模块所占的权重.通过判断网络模块给出的异常值M是否超过阈值来判断用户是否有主动产生流量的行为, 如果有, 则以网络模块为主, α < β , 且当网络模块异常值超过阈值时, 立即报警.否则, 以用户行为模块为主, α > β , 且当用户行为模块异常值超过阈值时, 立即报警, 或者总体异常值超过阈值时, 并报警.
本文采集正常用户键入以下17个双键组合的击键时间信息作为正常模型, 在实验阶段, 使用一份包含40条Linux shell命令的脚本作为测试数据.该子模块使用的测试脚本中所包含的Linux shell命令涵盖了这17个双键组合, 并且又能反映出这些双键组合对应的命令所使用的频度.
其中17个双键组合如下:
ca cd cp fi gr ll ls mk ps pw rm ro st su ta vi wh
该模型会实时计算出当前用户击键信息与样本的击键信息的偏差值K, 一旦K 值超过阈值C(C=60), 则产生报警, 此处设定的报警行为是锁屏.对应于1.2.2节提到的算法中所涉及的参数, 在本文实验中, 这些参数的赋值如下:阈值D1=100, D2=2, 梯度值E1=20, E2 =3.
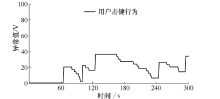
首先让正常用户键入以上提到的shell命令脚本, 没有出现误报.测试结果如图3所示, 然后让其他用户输入测试脚本中的命令到命令行, 最终分别对17名用户进行了测试, 其中有一名用户未能识别, 其余16名用户全部识别出来, 检测率为94.1%.
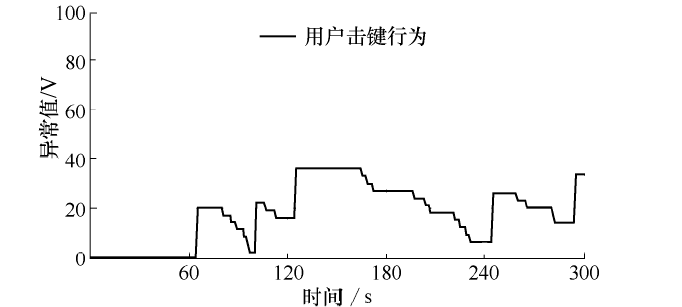 | 图3 正常用户击键测试Fig.3 Key stroke test of a legal user |
该实验首先以正常用户在11 d内的流量建立正常用户流量模型, 接着实时采集单位时间间隔内的流量与正常模型进行偏差值计算.本实验中选取T为1 min, 即实时采集1 min以内的流量进行监控.对该模块进行了7 d的测试数据收集工作, 用于确定阈值, 每天从上午9点开始至晚上22点结束, 共得到5 192个结果, 在此期间内, 随机选取某些时刻作为异常点, 人为引发一些网络流量异常(比如连续打开大量网页, 连续下载大量文件等)对于得到的测试数据, 对其进行了统计分析, 得到结果如表1所示.
| 表1 偏差值统计 Tab.1 Statistical list of deviation |
表1中的偏差值代表的是在单位时间内实时采集的流量向量与正常模型中流量向量的偏离程度.统计这些偏差值的意义在于确定检测算法中的阈值.
首先, 将产生的偏差值分成两种情况:
1)偏差值产生的时候, 用户有主动产生流量的行为, 例如浏览网页或者下载文件等.
2)偏差值产生的时候, 流量产生自后台软件, 用户无主动产生流量行为, 例如用户可能只是在编辑某些文件, 查看资料等.
表1中的数据的范围跨度是通过将所有数据绘制成直方图, 利用直方图确定各个数据段的分布情况, 最终选定数据范围跨度为500。另外, 本文认为使用偏差值的原始数据比使用缩放后的数据更能反映出网络流量的状态变化, 所以数据范围跨度略显偏大。表1中的百分比指各个偏差范围内, 实时捕获的流量在总体流量中的比例。
接着按照表1的数据, 把第1类情况对应的偏差值上限定为1 000, 第2类定为500, 因此综合起来, 将在1.3.2节中提到阈值U 定为1 000, R 定为50.
在开启该网络异常检测模块后, 让合法用户按照正常上网习惯, 使用4 h, 从上午9点至11点及从下午3点到5点, T为1 min, 即实时监测1 min以内的流量, 进行偏差计算.最后得到240个数据点, 其中出现7次误报.误报率为2.9%.
分别对其他8名用户进行了测试, 在测试过程中, 让这8名用户按照自己的上网习惯操作电脑, 操作时间上限为30 min, T 取1 min, 即实时监测1 min以内的流量, 进行偏差计算, 如果在操作时间内, 模块未报警, 则认为识别失败, 反之则算成功.
在测试中, 8名用户全部被识别, 系统报警的时刻都在使用后的第2~5 min.检测率为100%.
两个子模块分别实时采集用户行为信息和网络流量信息, 得到两个异常分值, 最后总体异常分值由两个子模块分值加权得到.其中, 两个子模块的权重(α , β )值在初始时都设为1, 在实时计算总体异常值时, 根据两个子模型的异常值, 动态调整权重.
从用户行为实验与网络流量实验的用户中, 选取了8名用户进行总体测试实验, 8名用户都能被识别, 检测率为100%.特别地, 在这8名用户中, 选取了在用户行为实验中未能被识别的用户(称为用户W)再次进行测试.
让用户W再次输入用户行为实验中的脚本, 系统未能识别, 用户W继续操控计算机, 他不仅能输入命令, 也能进行任何上网操作, 由于用户W在接下来的操作中, 使用计算机浏览了正常用户不常访问的网站, 使得系统通过网络模块成功识别用户W, 并报警.
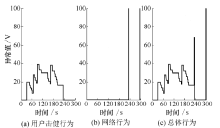
图4(a)表示用户W在总体实验中, 用户行为实验阶段的异常值变化曲线, 可以很明显看出用户行为模块异常值并未超过给定阈值(阈值设定为60), 即用户行为模块并未识别出用户W.图4(b)代表网络模块实验阶段的异常值变化曲线, 可以很明显的看出, 网络模块异常值已达到阈值(阈值为100), 即网络模块识别出用户W.
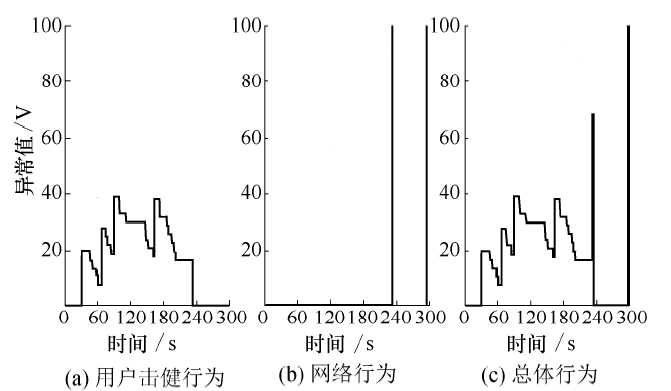 | 图4 用户W总体实验Fig. 4 Overall test of user W |
由于本文提出的模型由两部分组成, 因此需要从两方面进行分析:
1)当用户无明显导致产生网络流量行为时, 本模型误报率来自于用户行为模块, 实验表明:本模型在此种情况下, 能够实现零误报, 检测率为94.1%.
2)当用户有明显导致产生网络流量行为时, 本模型误报率来自于网络模块, 由实验可以得知误报率为2.9%, 需要注意的是, 网络模块的误报率与网络模块的样本能否准确代表正常用户行为模型有关, 本文网络模块的样本是正常用户11 d内的网络流量数据, 如果延长样本的采集时间, 例如样本为正常用户30 d内的网络流量数据, 那么能进一步降低误报率.检测率方面, 在多信息源模型中, 信息源之间存在互补关系, 当某些异常能绕过一种信息源检测模型时, 可依靠其他信息源对其进行检测, 从而提高检测率.
1)提出利用用户行为和网络行为融合模型结合K-NN算法分别对多种信息源建模, 并进行异常检测, 子模块之间独立工作, 互不影响, 而总体异常检测结果可以通过综合各个子模块的检测结果来提高检测率, 降低误报率.
2)本文使用的样本数据来源于真实环境中, 更加符合实际情况.在数据采集过程中, 不影响用户的正常使用.因此本文的研究结果更加真实有效, 具有可行性.
3)实验结果表明:综合利用多种信息源进行异常检测能弥补单一信息源模型的不足, 提高异常检测率.
在后续工作中, 将挖掘更多的数据源并使用更加有效的检测方法来进一步提高异常检测的准确率.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|